텍스트마이닝을 활용한 품질 4.0 연구동향 분석
Understanding of the Overview of Quality 4.0 Using Text Mining
Article information
Trans Abstract
Purpose
The acceleration of technological innovation, specifically Industry 4.0, has triggered the emergence of a quality management paradigm known as Quality 4.0. This study aims to provide a systematic overview of dispersed studies on Quality 4.0 across various disciplines and to stimulate further academic discussions and industrial transformations.
Methods
Text mining and machine learning approaches are applied to learn and identify key research topics, and the suggested key references are manually reviewed to develop a state-of-the-art overview of Quality 4.0.
Results
1) A total of 27 key research topics were identified based on the analysis of 1234 research papers related to Quality 4.0. 2) A relationship among the 27 key research topics was identified. 3) A multilevel framework consisting of technological enablers, business methods and strategies, goals, application industries of Quality 4.0 was developed. 4) The trends of key research topics was analyzed.
Conclusion
The identification of 27 key research topics and the development of the Quality 4.0 framework contribute to a better understanding of Quality 4.0. This research lays the groundwork for future academic and industrial advancements in the field and encourages further discussions and transformations within the industry.
1. 서 론
4차산업혁명 기술(예: 빅데이터, 인공지능, 블록체인 등)의 발전으로, 기업의 디지털 전환이 가속화되고 있다(Verhoef et al., 2021). 이에 따라 기업 내 환경(예: 공정, 기계, 작업자 등)에서 여러 종류의 데이터를 수집할 수 있으며, 이를 빅데이터 및 인공지능 기술을 통해 분석함으로써 기업 품질 활동(예: 기업의 공정 문제 해결, 프로세스 개선 등)에 큰 변화가 일어나고 있다(Lee and Cho, 2021; Seo et al., 2023). 이러한 변화를 학계에서는 품질 4.0(Quality 4.0)이라 하며, 최근 품질 4.0의 개념을 정의하기 위한 여러 선행연구가 수행되었다(예: Dias et al., 2022; Maganga and Taifa, 2022; Sader et al., 2022; Seo et al., 2023). 선행연구에서 품질 4.0은 다양하게 정의되어 왔는데, 그 공통점은 4차산업혁명 기술에 기반해 공정의 연결성, 지능화를 통해 데이터 기반의 의사결정을 수행하고, 더 나아가 공정의 자동화, 최적화를 통해 기업의 성과를 향상시키는 패러다임이라는 것이다.
품질 4.0은 4차산업혁명 관련 인프라 기술(예: 정보기술, 운영기술) 간의 연결과 이들 간의 연계 및 통합을 통해 달성된다(Maganga and Taifa, 2022). 또한 기업의 추진 전략, 방법론, 비즈니스 모델 유형, 데이터 기반의 의사결정 및 품질을 중시하는 문화, 기술 교육, 리더십 정립 등이 품질 4.0 달성에 큰 영향을 미친다(Seo et al., 2023). 품질 4.0 달성에 핵심 역할을 하는 여러 요인을 이해하기 위해서는 품질 4.0의 개념을 이해하는 것에서 더 나아가 품질 4.0과 관련된 기반 기술, 모델, 구성요소 등의 연관성을 이해해야 하며, 이해 결과(예: 품질 4.0 관련 기술, 적용 분야, 핵심요인, 도전과제 등)를 토대로 품질 4.0 달성을 위해 노력해야 한다.
선행연구 리뷰를 통해 이러한 품질 4.0 관련 핵심 요인을 통합적으로 이해할 수 있다. 그러나, 관련된 수많은 연구 문서가 존재하므로 이러한 문서를 모두 분석하고, 이해하기는 쉬운 일이 아니다. 하나의 예로 Google Scholar에서 {“quality 4.0”}의 키워드로 검색해보면 약 2730건 이상의 문서가 검색되며(23년 9월 기준), 이 문서들은 컴퓨터공학, 산업공학, 경영학, 사회학의 다양한 학문 분야에 걸쳐있어, 통합적인 관점에서 품질 4.0 관련 선행연구의 동향을 파악하는 것이 쉽지 않다. 이에 본 연구에서는 SCIE(Science Citation Index Expanded), SSCI(Social Science Citation Index), ESCI(Emerging Sources Citation Index) 데이터베이스에서 품질 4.0 관련 주제로 검색되는 1234편의 논문을 수집하고, 이를 텍스트마이닝 및 기계학습 방법을 활용하여 분석을 수행하였다. 특히, Spectral Clustering(Von Luxburg, 2007), Latent Dirichlet Allocation(LDA)(Blei et al., 2003), Non-negative Matrix Factorization(NMF)(Lin, 2007) 기법을 사용하여 품질 4.0 관련 27개의 연구토픽을 파악하였다. 또한 네트워크 분석 방법을 통해 27개 연구토픽 간 연관관계를 분석하였으며, “기반 기술-방법론 및 전략-달성 목적-적용 산업”으로 구성된 품질 4.0의 멀티레벨 프레임워크를 제안하였다.
본 연구는 텍스트마이닝 및 기계학습 방법론을 활용하여 품질 4.0의 연구동향을 분석하고, 품질 4.0과 관련된 다양한 관점을 통합적으로 이해하기 위한 기반 마련을 시도한 점에서 기여가 있다. 본 연구의 결과물은 품질 4.0 관련 선행연구의 개관(overview; big picture)을 나타내며, 이는 연구자의 품질 4.0 연구 수행을 촉진하는데 기초자료로 활용될 것으로 기대한다.
본 논문의 구성은 다음과 같다. 2절에서는 품질 4.0 관련 선행연구를, 3절에서는 연구 수행 방법을 설명하고, 4절은 연구 결과를 서술한다. 마지막으로 5절은 본 연구의 기여 및 향후 과제를 서술한다.
2. 문헌 리뷰
품질 4.0은 4차산업혁명 시대에 등장한 새로운 품질 패러다임으로, 4차산업혁명 기술을 기업의 품질 활동에 적용하는 것을 의미한다(Jacob, 2017). 이를 통해 기업의 공정 운영 목표(예: 저품질 비용 감소, 품질 문제 원인 추적 등)를 달성함으로써 기업 경영의 혁신을 가속화한다(Maganga and Taifa, 2022). 품질 4.0 달성을 위해서 기업은 디지털화를 통해 데이터를 수집 및 분석함으로써 데이터 기반의 의사결정을 수행하는 것이 필요하며, 여러 기술(예: 정보기술, 운영기술)을 연결하여 기능부서 간의 통합을 유도하고, 리더십을 바탕으로 새로운 조직문화를 구축하는 것이 필요하다(Seo et al., 2023).
여러 선행연구에서 품질 4.0의 개념, 구성요소, 핵심요소 등에 대해 제시하고 있다. 품질 4.0은 기존 품질 연구에서 중요시하던 품질관리(Quality Control), 품질보증(Quality Assurance), 종합적 품질경영(Total Quality Management)을 모두 포괄하는 개념이다(Dias et al., 2022). 이는 제품, 공정, 회사의 품질을 관리하는 것에서 더 나아가 제품의 고객, 공급자의 품질까지 모두 관리하는 것을 의미한다(Sader et al., 2022). 또한 기존의 품질관리 방식(예: 통계 분석, 샘플링, 수동적 관리 수행, 전문가 중심의 품질 관리 등)에서 데이터 기반의 품질관리 방식(예: 인공지능 및 빅데이터 시스템을 통한 실시간 전수 데이터 분석, 스마트 디바이스의 활용, 능동적 관리 수행, 모든 이해관계자들의 의사를 반영한 품질 관리 등)으로 변화하고 있다(Sader et al., 2022). 이 때 자동 로봇, 가상 물리시스템, 인공지능, 클라우드 및 퀀텀 컴퓨팅, 증강 및 가상현실, 사이버 보안, 사물인터넷, 기계학습, 시뮬레이션 등의 4차 산업혁명 기술이 품질 4.0 달성에 큰 역할을 한다(Jeong and Kim, 2023; Küpper et al., 2019).
품질 4.0 달성에 핵심역할을 하는 요소로 Seo et al.(2023)은 데이터 획득 및 분석기술, 연결과 통합, 리더십과 조직문화를 제시하였다. Sader et al.(2022)은 기술, 공정, 사람 관점에서 핵심요소를 제안하였고, 기술 내에서는 데이터, 분석 기술, 앱 개발, 연결성을, 공정 내에서는 관리 시스템, 컴플라이언스 준수, 문화를, 사람 내에서는 리더십, 협력, 능력 보유의 중요성을 강조하였다.
성공적인 품질 4.0 달성을 위한 전제 조건은 품질 4.0과 관련된 다양한 관점과 지식을 파악하고, 이를 여러 관점과 수준으로 분석하고 통합하는 것이다. 여러 선행연구에서 품질 4.0의 다양한 구성요소, 핵심요소를 제시하고 있지만, 이들 간의 연계성 및 전체적인 개요를 제공하지 않는다는 한계가 있다. 품질 4.0 달성을 위한 기술 개발에서부터 관련 방법론 및 전략, 추진 목적, 적용 산업의 이해에 이르기까지 품질 4.0의 전체 스펙트럼을 이해하는 것은 성공적인 품질 4.0 달성을 촉진하는 데 중요한 역할을 한다. 이에 본 연구에서는 텍스트 마이닝과 기계학습 알고리즘을 활용하여 방대한 양의 연구논문을 분석함으로써 품질 4.0 관련 연구토픽과 이들 간의 연관관계를 파악하고자 하였다. 이는 품질 4.0의 전체 스펙트럼 및 연구동향을 이해하고, 추후 품질 4.0의 연구 방향성을 모색하는데, 기초 자료로 활용될 것으로 기대된다.
3. 연구 방법
본 연구에서는 Lim and Maglio(2018)이 제안한 문헌 데이터 분석 방법론을 활용하여 품질 4.0의 연구현황을 파악하였다. 방법론은 4단계로, (1) 논문 데이터 수집 및 전처리 수행, (2) 주요 설명 단어 추출, (3) 논문 분류 및 연구 토픽별 주요 키워드 파악, (4) 연구토픽 간의 네트워크 분석 수행 및 해석의 단계로 구성된다. 본 연구에서는 python 프로그램 및 공개된 라이브러리(nltk, TextBlob, networkx, scikit-learn)을 활용하여 분석을 수행하였다.
단계 1에서는 Clarivate Analytics사의 저널 논문 데이터베이스인 Web of Science Core Collection으로부터 품질 4.0 관련 논문 데이터를 수집한다. 본 연구에서는 검색 필드를 “주제(TS)”로 선정하고, 4차산업혁명 관련 키워드와 품질 관련 키워드를 조합하여 품질 4.0 관련 논문을 검색하였다. 이 때 검색 쿼리는 다음과 같다. TS = ((“Industry 4.0” OR “fourth industrial revolution” OR “industrial revolution”) AND (“digital quality” OR “quality” OR “quality approaches” OR “quality assurance” OR “quality control” OR “quality culture” OR “quality management” OR “quality principles” OR “quality tools”)) (23년 2월 28일 검색 수행). 학회논문 및 북챕터 논문을 제외한 저널 논문 중 특정 주제에 대한 연구 결과를 서술하는 article 유형의 논문만을 수집하였다(review, survey, editorial 유형 제외). 수집한 논문의 분석을 위해 논문의 제목, 초록, 저자들이 지정한 키워드 텍스트만을 발췌하였으며, 이는 기존의 문서 마이닝 연구에서 서지 정보 텍스트(제목, 초록, 키워드 등)만을 분석하여도 특정 주제의 연구현황을 파악하는데 충분하다는 선행연구가 다수 존재하기 때문이다(예: Lee and Moon, 2022). 결과적으로 총 1235편의 논문을 수집하였으며, 초록이 미기입된 논문 1편을 제외한 1234편의 논문을 분석 대상으로 선정하였다. 이후 데이터 분석을 위해 stop word 제거, tokenization, lemmatization 등을 수행하여 데이터를 전처리하였다.
단계 2에서는 수집된 논문 데이터로부터 품질 4.0을 설명하는 주요 설명 단어(significant word features)를 추출한다. 먼저 문서-단어 행렬을 사용하여 논문과 단어를 표현하였다. 이는 논문을 행에, 논문에서 사용한 모든 단어를 열에 위치시킨 후 교차하는 셀에는 특정 논문에 등장한 특정 단어의 중요도 값을 기록하는 방법이다. 분포 표현을 위해 문서 내 단어의 중요도 값을 산정하는 방식인 TF-IDF(Term Frequency-Inverse Document Frequency) 척도를 사용하였다. TF-IDF는 단어 중요도 값을 산정할 때 그 단어가 다른 논문에 등장할 경우 그만큼 하향시키고, 반대로 그 단어가 특정 논문에서만 등장한다면 그 문서에서의 중요도 값을 상향시키는 척도이다. 특히, TF-IDF 척도가 사용된 문서-단어 행렬에서 특정 논문에서만 다수 등장하는 단어(예: 저자가 정의한 약어), 어느 논문에서나 많이 쓰이는 단어(예: study, objective, implication 등)를 제외하고, 품질 4.0 논문을 대표하는 단어(예: quality, evaluation, manufacturing 등)만을 추출하여 주요 설명 단어를 선별하였다. Lim and Maglio (2018)에서는 두 개의 hyperparameters를 제안하였는데, 첫째는 각 논문의 토픽을 대표하는 단어 개수, 둘째는 대표 단어가 등장하는 논문 편수이다. 해당 hyperparameter는 5개 척도에 기반하여 최적화되며, 이를 통해 품질 4.0 논문을 대표하는 단어만을 선별할 수 있다. 각 논문의 대표 단어 수를 1~20개로 변경하면서 평균 중요도의 변화를 관찰함으로써 대표 단어를 선별하였다. 이 때 평균 중요도는 5개 척도에 의해 정의되며, 이는 한 단어 특성의 TF-IDF 평균값(#1), 한 단어 특성과 다른 단어 특성들과의 코싸인 유사도 평균값(#2), 한 단어 특성과 다른 특성들의 중심값 간의 코싸인 유사도 값(#3), 한 단어 특성과 다른 특성들과의 내적 결과의 평균값(#4), 한 단어 특성과 하나의 단일 주제에 대한 LDA 값(#5)을 포함한다. <Figure 1>은 5개 척도를 활용한 최적화 결과를 나타낸다. 5개 단어(K5)와 4개 단어(K4)에서 중요도의 차이가 모든 척도에서 크게 발생(elbow point)하여 하나의 논문을 5개의 대표 단어(hyperparameter 1)로 설정하였다. 또한 여러 실험의 반복으로 2편 이상의 논문(hyperparameter 2)에서 대표 단어가 언급되어야 함을 파악하였다. 결론적으로 당초 11727개의 단어 중 903개를 주요 설명 단어로 선별하였다.

Changes in importance according to significant word extraction from each article
단계 3에서는 주요 설명 단어 903개를 변수로 활용하여 1234편의 논문을 분류한다. 하나의 논문은 하나의 연구 토픽을 갖는다는 가정 하에 군집분석 유형 중 하나인 Spectral Clustering을 사용하여 논문을 분류한다. 해당 알고리즘은 데이터의 유사도 행렬으로부터 추출된 Laplacian 행렬을 사용하여 그래프 기반으로 군집화를 하는 방법이다. 이는 데이터들 간 관계 네트워크를 표현하는 고유공간(eigenspace)에서의 정보를 기반으로 데이터를 분류하는데, 문서 분류에 성능이 좋다고 알려져 있다. 수집한 1234편의 논문들에 최소 2개 이상, 최대 40개 이하의 토픽이 있다는 가정 하에 각 군집수별 반복 횟수를 200회로 지정하여 분석을 수행하였고, 실루엣스코어 값(Rousseeuw, 1987)을 기준으로 군집의 개수를 정하였다. <Figure 2>의 좌측 그래프를 확인했을 때 실루엣스코어 기준 최적의 군집 수는 32개이다. 그러나, 군집에 할당되는 논문 편수가 너무 적으면 해당 군집의 연구토픽의 범위 및 내용이 너무 협소해지는 특성이 존재하여, 할당된 논문의 편수가 10편 미만인 군집은 유사도가 높은 군집에 강제 할당하였다. 최종적으로 5개의 군집이 강제 할당되어 총 27개의 군집이 도출되었다. 즉, 1234편의 논문을 27개 군집으로 분류한 뒤, 각 군집의 연구토픽을 파악하기 위해 토픽모델링 기법(LDA, NMF)을 활용하여 군집을 대표하는 주요 단어들을 도출하였다. LDA, NMF 수행 시 토픽의 개수는 1로 고정한 뒤 Spectral Clustering의 군집 결과를 그대로 활용하는 방법으로 각 군집별 주요 단어 분포를 살펴보았다. <Figure 2>의 우측 그래프는 클러스터링 수행 결과의 해석 과정을 나타낸다. 행렬의 행과 열은 모두 문서를 나타내며, 교차하는 셀은 문서 간 코싸인 유사도가 전체 평균값보다 클 경우 검은색, 반대의 경우 흰색으로 표기된다. 결과적으로 클러스터의 밀도는 이에 속한 논문들의 주제 간 응집도를 나타낸다. 군집 내 TF-IDF의 평균값과 각 논문의 코싸인 유사도를 계산한 뒤, 이를 기준으로 군집별 대표 및 비대표 논문을 구분하여 비교하였다. 대표 논문들의 제목, 초록, 키워드를 살펴보는 정성적 분석 과정을 통해 군집의 연구토픽을 충실히 이해하고, 토픽의 이름을 명명하였다. 토픽 도출의 상세 결과는 4.2절에서 서술한다.

Evaluation and interpretation of the clustering results
단계 4에서는 단계 3에서 도출한 연구토픽을 해석하고, 연구토픽 간 네트워크 분석을 통해 토픽 간의 연관성을 파악한다. 그림 내 하나의 노드는 하나의 연구토픽을, 노드의 크기는 각 연구토픽에 할당된 논문 개수의 비율을 나타낸다. 연구토픽 간의 연관성 파악을 위해 각 연구토픽(군집)의 중심점을 TF-IDF을 활용해 계산하고, 이 중심점을 활용하여 각 연구토픽 간의 코싸인 유사도를 계산한다. 코싸인 유사도 활용 시 모든 토픽이 연결되나, 본 연구에서는 주요한 연구토픽 간의 관계만 살펴보기 위해 코싸인 유사도 값을 기준으로 하여 각 연구토픽별 상위 3개의 연구토픽을 연결하였다. 즉, 하나의 연구토픽은 최소 3개의 연구토픽과 연결된다. 본 연구에서는 도출된 27개 연구토픽에 대한 네트워크 분석 수행 결과의 상세 내용은 4.3절에서 서술한다.
4. 연구 결과
4.1 품질 4.0 연구 문헌의 기술통계치 분석
<Table 1>은 논문 1234편의 지역(교신저자 소속기관의 국가 기준), 저널, 연구분야(Web of Science에서 제공하는 논문의 연구분야) 상위 10위를 나타낸다. 논문의 지역적 분포는 중국이 107편으로 가장 많았으며, 그다음으로 이탈리아(93편), 인도(86편), 독일(72편), 스페인(68편) 등으로 제조업을 주력으로 하는 국가들이 품질 4.0 연구를 활발히 하는 것을 알 수 있다. 논문의 연구분야 분포는 산업공학(181편)이 가장 많았으며, 그 다음으로 제조공학(175편), 전자/전기공학(164편), 컴퓨터공학(135편) 등으로 품질 4.0과 관련 깊은 제조업에서의 활용 사례, 품질 4.0 달성에 활용할 수 있는 4차산업혁명 기술 관련 연구가 많음을 알 수 있다. 특히, 산업공학, 제조공학 분야에서는 품질 4.0 달성을 위한 공정의 운영 관점에서의 연구가, 전자/전기공학 및 컴퓨터공학에서는 공정 구축을 위한 기술 간의 연결성과 지능화 방법 측면에서의 연구가 대부분을 차지하였다. 논문의 저널 분포는 Sustainability가 62편으로 가장 많았으며, 다음으로 Applied Science(53편), Sensors(51편), IEEE Access(40편) 순으로 많았다. 상위에 분포한 저널들은 주로 기술 개발, 기술 응용 등의 융합을 장려하는 저널들인데, 이를 통해 품질 4.0 연구는 다학제적, 융합적 연구임을 간접적으로 확인할 수 있다. 마지막으로 연도별 논문의 출판 수를 확인해 보면 2015년부터 2023년 2월 28일까지 약 8년간 품질 4.0 논문은 1편 → 8편 → 13편 → 71편 → 134편 → 231편 → 405편 → 371편으로 꾸준히 증가하는 것을 확인할 수 있다. 특히 최근 3년 이내에 논문 출간 수가 많이 증가하였는데, 이는 품질 4.0 관련 연구자들의 큰 관심을 의미한다.

Descriptive statistics with articles on Quality 4.0
4.2 연구토픽 도출 및 레벨 분류
논문 데이터 분석을 통해 파악한 품질 4.0 관련 27개 연구토픽(단계 3에서 도출된 27개 군집에 해당)은 <Table 2>와 같다(토픽 이름 옆 괄호 안 숫자는 토픽에 할당된 논문 수를 의미). <Table 2>의 연구토픽별 LDA, NMF로 추출한 주요 키워드, 연구토픽에 속한 논문들의 제목, 저널명, 초록 등의 내용을 검토한 결과 다음과 같은 해석을 할 수 있었다.

27 key topics in the Quality 4.0 literature
먼저, 27개 연구토픽을 성격에 따라 5개 레벨로 분류하였다. 멀티레벨 프레임워크는 연구 대상의 추상적 개념부터 구체적 실체까지의 관계를 통합적으로 표현 및 분석하는데 효과적으로 활용되어 왔다(예: Lim and Maglio, 2018). 이에 본 연구에서도 5개 레벨로 구성된 프레임워크를 도입하여 품질 4.0의 다양한 관점에 대해 폭넓게 이해하고자 시도하였다.
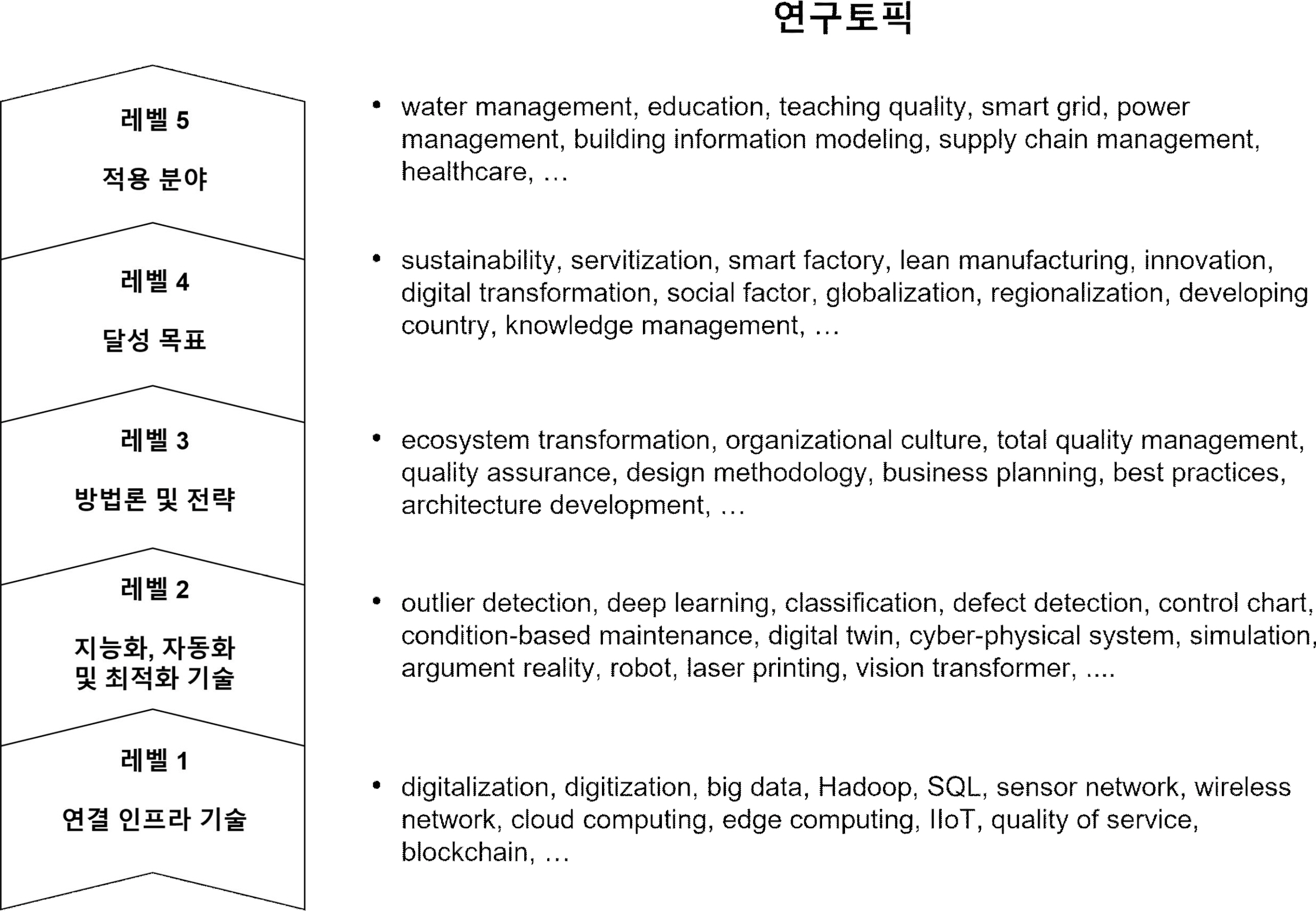
27개 연구토픽은 연결 인프라 기술(레벨 1), 지능화, 자동화 및 최적화 기술(레벨 2), 기업 성과 향상을 추구하기 위한 방법론 및 전략(레벨 3), 품질 4.0 달성 목적(레벨 4), 품질 4.0 적용 산업(레벨 5)으로 분류할 수 있다. 먼저 “연결 인프라 기술”은 <Table 2>의 디지털화(#1), 데이터 관리(#2), 네트워크 품질(#3), 클라우드 및 산업용 사물인터넷(#4)의 연구 토픽을 포함한다. 각 토픽을 상세하게 살펴보면, 디지털화는 정보와 데이터를 컴퓨터 기반의 형태로 저장, 처리, 전송 및 관리하는 과정을 의미하며, 전통적인 물리적 형태에서 디지털 형태로의 변환을 의미하여 최근 제조업에서 많이 시도하고 있다. 데이터 관리는 빅데이터 생애주기(수집-저장-분석-활용) 관점에서의 데이터 수집 및 저장을 위한 기술 관련된 토픽을 의미한다. 네트워크 품질은 빅데이터 생애주기 관리를 위해 필요한 네트워크의 품질을 의미하며 기존의 통신 산업에서 많이 언급되었던 패킷 손실, quality of experience, quality of service, network performance를 모두 포함한다. 마지막으로 클라우드 및 산업용 사물인터넷에는 실시간 분석에 활용되는 edge computing, cloud computing 등과 같은 컴퓨팅 패러다임을 포함한다. 이러한 기술들은 최근 물류, 시스템 관리 등에 다양한 분야에 활용되고 있어, <Table 2>에 관련 키워드가 포함된 것을 확인할 수 있다.
“지능화, 자동화 및 최적화 기술”은 <Table 2>의 모니터링 및 진단(#5), 기계학습 알고리즘(#6), 이상치 탐지(#7), 고장예지 및 건전성 관리(#10)의 기술 연구토픽을 포함한다. 이러한 4개 토픽은 데이터 분석 기술에 공통적으로 초점을 맞추고 있으며, 특히 이들은 4차산업혁명에서 강조되고 있는 인공지능과 매우 관련 깊다. 또한 이러한 토픽들은 제조업의 품질 향상과 밀접한 연관성이 있으며, 2절에서 언급한 품질관리, 품질보증, 종합적 품질경영을 달성하는데 활용 가능한 핵심 기술이다. 레벨 2에서는 앞의 4개 토픽 외 디지털 트윈(#8), 3D 프린팅 기술을 활용한 적측 제조(#9), 조립 라인에서의 로봇 활용(#11), 확장 현실(#12)의 기술 연구토픽도 포함한다. 이러한 토픽들의 공통된 특징은 데이터 분석 결과 활용 및 공정 최적화 관점에서 활용되는 기반 기술이라는 점이다. 이러한 기술들은 비교적 최신 기술이라 아직 성숙 단계에 도달하지 않았기 때문에 동일 그룹 내 다른 토픽보다 논문 출간 수가 적으며, 대부분의 논문은 기술을 활용하기 위한 고려 사항과 적용 가능성을 다루고 있다.
“방법론 및 전략” 레벨은 품질 4.0 달성을 위해 활용 가능한 공학 및 비즈니스 방법론을 의미한다. 해당 방법론을 활용하여 기업은 성과 향상, 지속가능성 확보 등과 같은 성과 향상을 이룰 수 있다. <Table 2>의 품질 4.0 달성에 필요한 공정 및 품질 시스템 디자인 및 개발 방법론(#13), 비즈니스 전략 수립 및 계획(#16), 조직 문화 조성 방안(#17)의 연구토픽이 해당 레벨에 속한다. 디자인 및 개발 토픽에서는 생산 공정 및 관리를 위한 디자인, 품질 4.0 달성을 위한 시스템 디자인 방법론 등의 내용을 포함한다. 비즈니스 전략 수립 및 계획 토픽에서는 자원 활용 관점에서의 공급자의 전략적 행동, 제조업의 서비스화 전략 등의 내용을 포함하며, 마지막으로 조직 문화 조성 방안 토픽에서는 품질 4.0 달성을 위해 조직 구성원들의 의욕 고취, 준수해야 할 사항 등을 다룬다. 또한 방법론 외 제조업에서의 품질 4.0 달성을 위해 고려해야 할 사항(#14), 품질 4.0 개념 정의 및 특징 도출(#15)과 같이 품질 4.0 달성을 위해 참고 가능한 연구토픽도 해당 레벨에 포함된다. 이들 토픽에 속한 논문들은 품질 4.0 용어가 처음 등장한 시기부터 최근까지의 품질 4.0 개념의 변화와 특징 등을 다루고 있다.
“달성 목표” 레벨은 품질 4.0을 통해 기업이 궁극적으로 추구하고자 하는 방향 및 목표를 의미한다. <Table 2>의 지속가능성(#18), 스마트 제조(#19), 린 제조(#20), 혁신(#21), 사회 및 경제적 효과(#22)의 연구토픽을 포함한다. 이러한 토픽들의 공통된 특징은 기업의 변화 및 성장, 효율성 및 품질 달성, 사회 및 환경적 영향, 경쟁 우위 달성을 위한 상위 레벨에서의 전략 방안을 논한다는 점이다.
마지막으로 “적용 산업” 레벨은 품질 4.0이 적용된 분야 및 사례를 포괄한다. 교육(#23), 에너지(#24), 건설(#25), 음식물류(#26), 헬스케어(#27) 산업의 연구토픽을 포함하며, 각 산업에서의 4차산업혁명 기술의 활용 방안, 기대효과, 품질에 미치는 영향 등의 내용을 주로 다룬다.
<Figure 3>은 레벨별 연구토픽의 분류 결과를 예시한다. <Figure 3>에 나타난 바와 같이, “적용 산업(레벨 5)“의 연구토픽은 기업 내 환경이 구축된 상황에서 품질 4.0 달성 추구를(상위 계층), “달성 목표(레벨 4)“의 연구토픽은 품질 4.0 달성 노력의 목표를, “방법론 및 전략(레벨 3)”의 연구토픽은 목표 달성을 위한 핵심 방법론 및 전략을, “지능화, 자동화 및 최적화 기술(레벨 2)”과 “연결 인프라 기술(레벨 1)”의 연구토픽은 품질 4.0 수행을 위해 필요한 기반 및 수단(하위 계층)을 대표하는 것으로 해석된다.
Enabler–business–goal–application framework for Quality 4.0
도출된 5개 레벨 내 27개 연구토픽은 2절에 서술된 선행연구의 품질 4.0 관련 구성요소 및 핵심요소를 모두 포괄한다. 예를 들어 Seo et al. (2023)에서 제안한 데이터 획득 및 분석기술은 레벨 1, 2에, 연결과 통합은 레벨 1, 2, 4에, 리더십과 조직문화는 레벨 3에 해당한다. Sader et al. (2022)에서 제안한 기술 내 데이터, 분석 기술, 앱 개발, 연결성은 레벨 1, 2에, 공정 내 관리 시스템, 컴플라이언스 준수, 문화는 레벨 3, 4에, 사람 내 리더십, 협력, 능력 보유는 레벨 3, 4에 해당한다.
4.3 연구토픽 간의 관계 해석
<Figure 4>는 품질 4.0 관련 27개 연구토픽 간의 네트워크 관계를 나타낸다. 노드는 각 연구토픽을, 노드의 크기는 각 토픽에 할당된 논문 개수의 비율을, 노드의 색은 레벨을, 마지막으로 노드 간 연결된 선은 연구토픽 간의 관계성을 나타낸다. <Figure 4>에 대한 해석 예시는 다음과 같다.

Relationship among the 27 research topics
먼저 연결 인프라 기술(그림 내 LV1로 표기) 및 지능화, 자동화 및 최적화 기술(LV2)은 품질 4.0 환경을 구축하는 기반 기술을 의미한다. 기술 간의 연계 및 통합으로 품질 4.0이 달성되므로 이들은 서로 관계가 깊은 것을 알 수 있다. 특히 초록색 노드의 경우 밀집해 있는 것을 확인할 수 있으며, 이는 공정의 지능화, 자동화, 최적화는 하나의 기술이 아닌 여러 기술이 통합, 연계되어 구현되는 것을 의미한다. 또한 이러한 기술들은 공정 및 품질 시스템의 디자인, 개발에 큰 역할을 하므로 디자인 및 개발 방법론 연구토픽(#13)과 연결된 것을 확인할 수 있다. 방법론 및 전략(LV3)은 가운데 위치하여 모든 레벨의 연구토픽과 연결된 것을 확인할 수 있으며, 이는 방법론 및 전략이 품질 4.0 달성에 핵심 역할을 하는 것으로 예측할 수 있다. 특히, 비즈니스 전략, 조직 문화 조성 관련 연구토픽(#15, 16, 17)은 지속가능성, 혁신, 사회적/경제적 기여 연구토픽(#18, 21, 22)과 매우 밀접한 관계를 갖는다. 마지막으로 달성 목표(LV4)와 적용 산업(LV5)은 레벨 1~3의 기술, 방법론, 전략을 활용하여 품질 4.0을 달성하거나, 여러 산업에 적용되기 때문에 특정 위치에 밀집되어 있는 것이 아닌, 여러 군데 흩어져 있는 것을 확인할 수 있다. 이 중 센서를 활용한 에너지 측정이 매우 중요한 역할을 하는 에너지 산업(#24)은 연결 인프라 기술 중 센서 네트워크, 데이터 관리 기술과 연결되었고, 공급사슬망 관리가 핵심인 음식 물류 산업(#26)은 디지털화 기술과 연결되었다. 마지막으로 헬스케어 산업(#27)은 최근 부각된 원격 의료의 중요성으로 인해 IoT 및 데이터 관리 기술, 그리고 비즈니스 전략 주제와 연결된 것을 확인할 수 있다.
4.4 레벨별 연구토픽 트렌드 해석
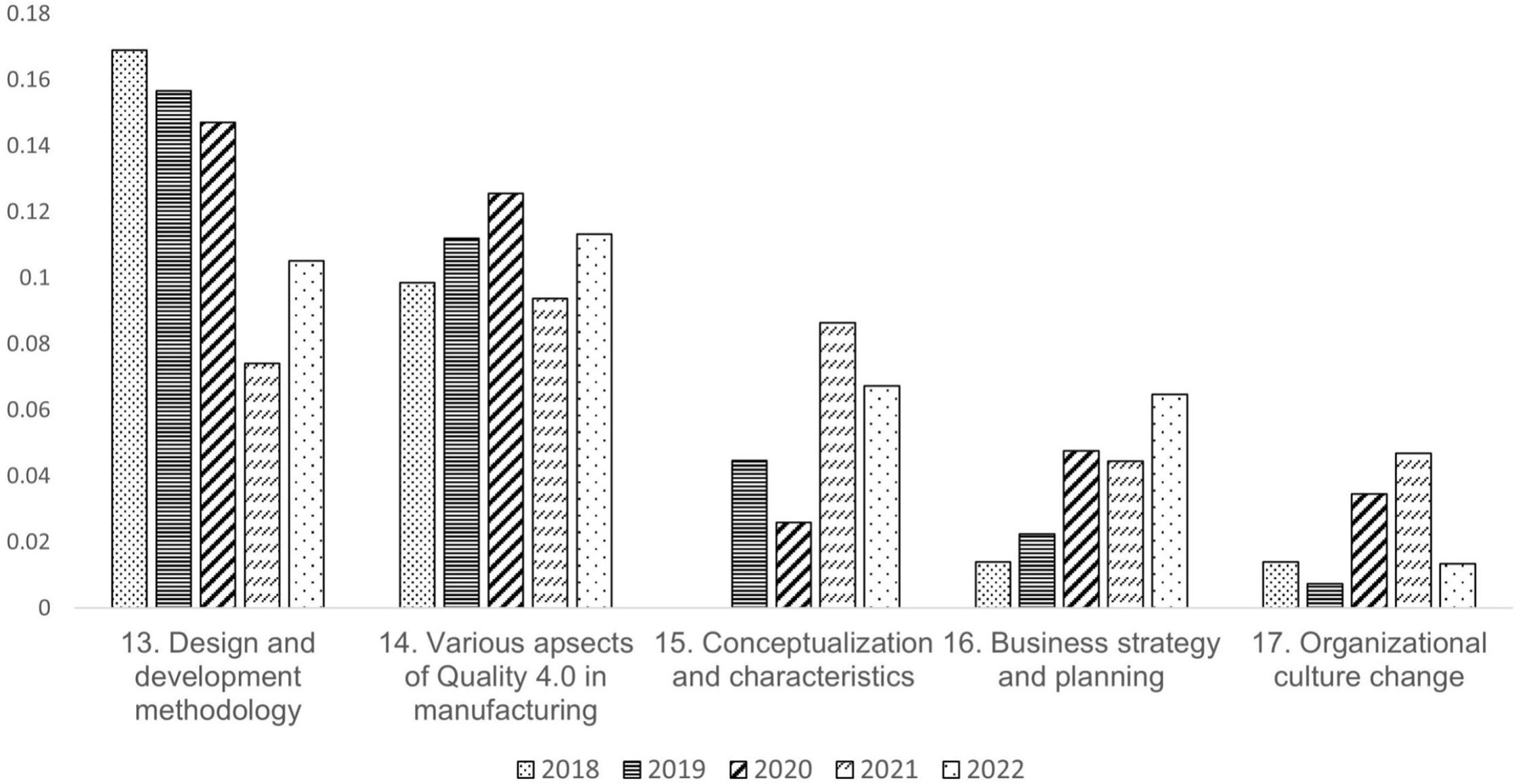
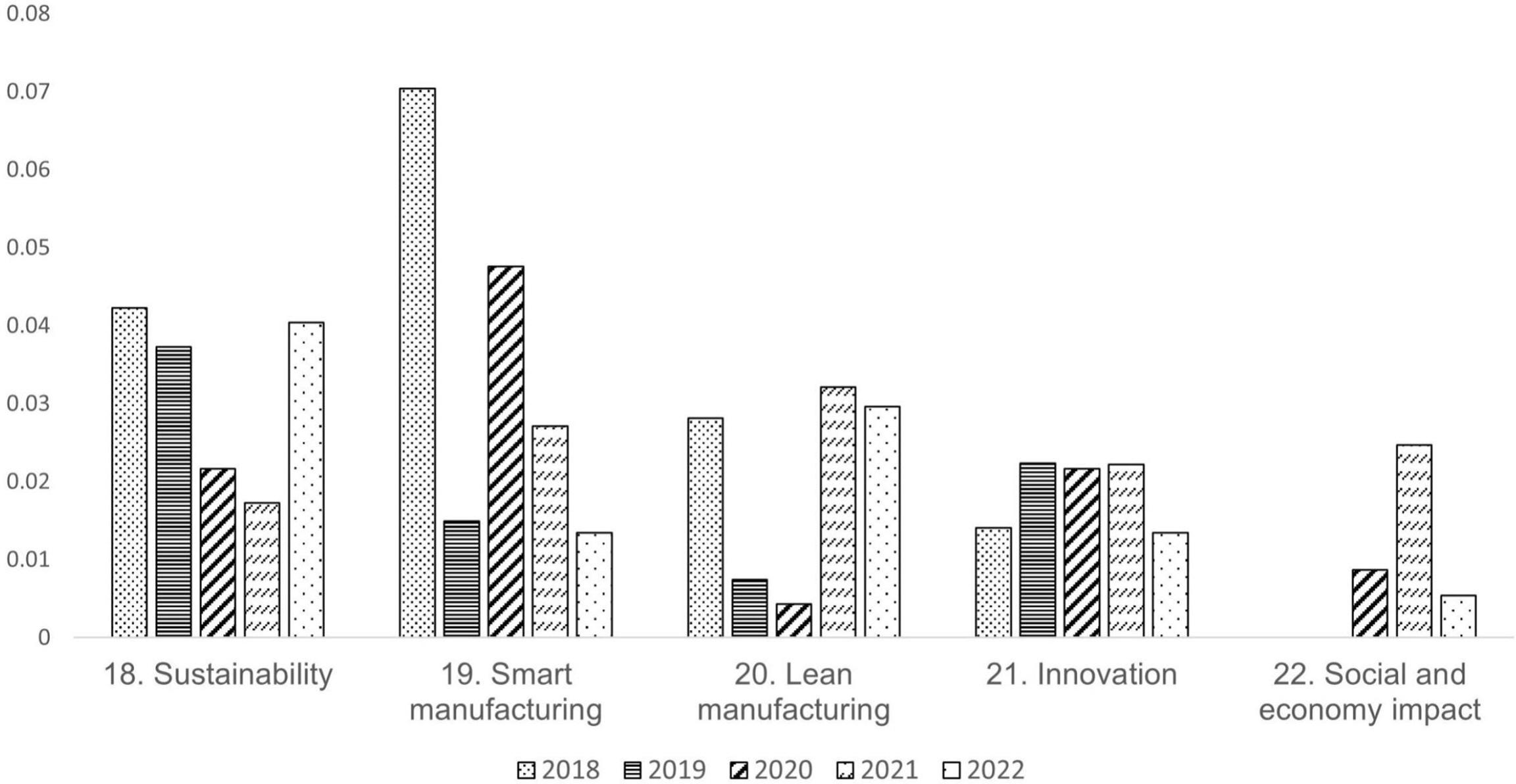
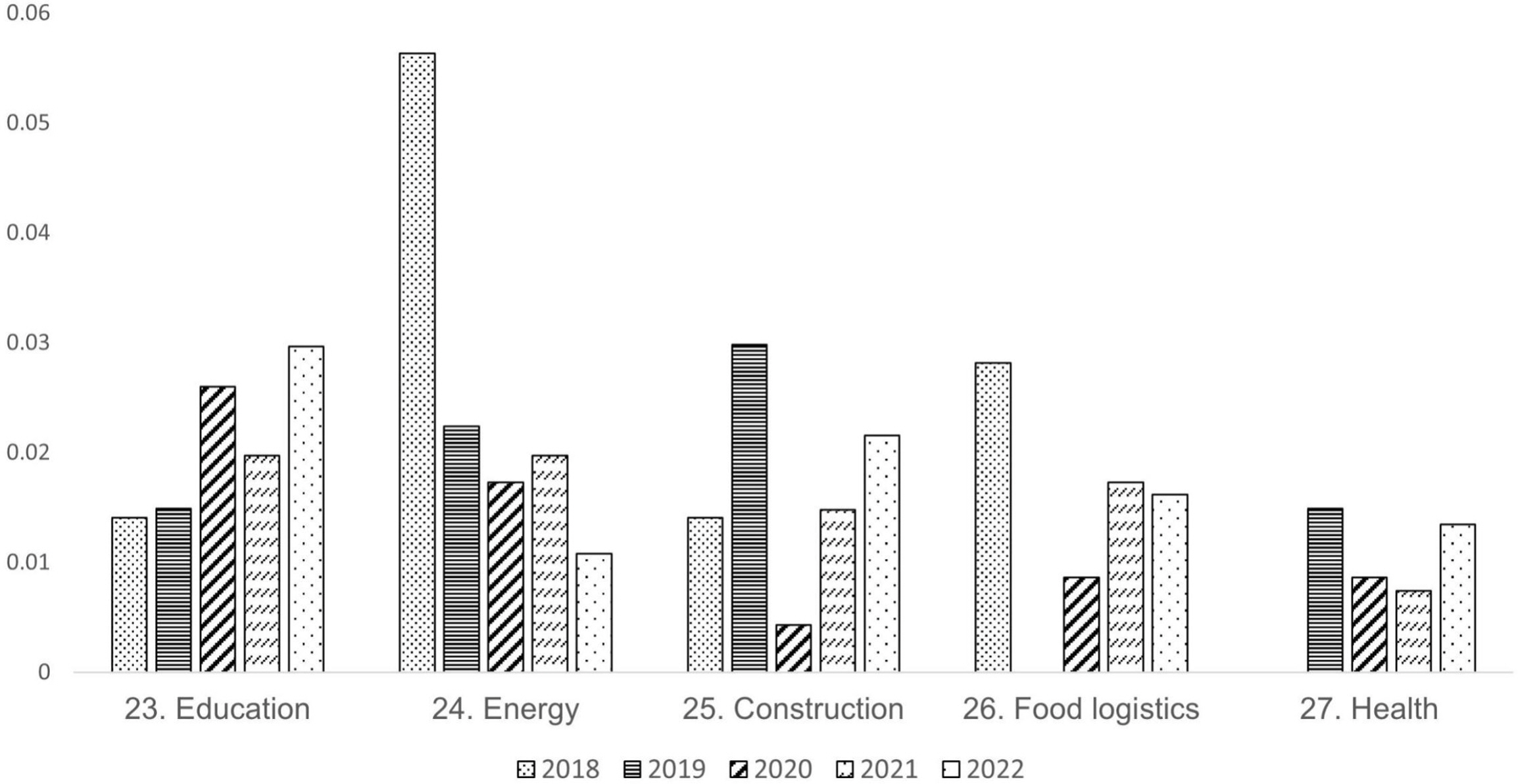
최근 5년(2018~2022년)의 품질 4.0 관련 논문의 출간 건수를 활용하여 연구레벨별 연구토픽의 트렌드를 분석하였다(2017년까지의 논문 수는 많지 않아, 최근 5년으로 한정). 매년 품질 4.0 관련 논문의 수가 증가하고 있는 만큼, 특정 연구토픽의 절대적 논문 수가 아닌 해당연도의 논문 수 비율 값을 기준으로 트렌드를 분석하였다. 5개 레벨 내 27개 연구토픽의 트렌드는 <Figure 5~9>와 같다.

Trend of level 1 research topics

Trend of level 2 research topics
Trend of level 3 research topics
Trend of level 4 research topics
Trend of level 5 research topics
연결 인프라 기술은, 클라우드, 네트워크, 빅데이터 관련 기술들에 대한 논문의 수는 줄어들고 있고, 디지털화 기술은 지속적인 관심을 받고 있음을 알 수 있다(<Figure 5>). 한편 지능화, 자동화 및 최적화 기술은 기계학습 알고리즘, 이상치 탐지와 같은 연구토픽이 점점 더 주목받고 있음을 알 수 있다(<Figure 6>). 이는 공정 및 시스템에서 수집되는 데이터 기반의 품질 관리에 활용할 수 있는 알고리즘이 많이 개발되고 있음을 시사한다. 로봇, 확장현실과 같은 연구토픽은 아직 개발의 완성도가 높지 않아 공정 및 시스템에 적용하는데 한계가 있어, 상대적으로 적은 논문 편수가 출간된 것을 확인할 수 있다. 방법론 및 전략은 디자인 및 개발 방법론 논문의 출간 비율이 매우 높으나, 시간이 흐르면서 논문의 수가 줄어드는 것을 확인할 수 있다(<Figure 7>). 한편 품질 4.0 달성을 통한 수익 창출이 중요한 이슈로 떠오르면서 비즈니스 전략 및 기획 연구토픽의 논문의 수가 증가함을 확인할 수 있다. 과거에는 품질 4.0의 개념, 추진 방향성이 매우 중요했던 반면, 이제는 품질 4.0을 통한 수익 창출의 관심도가 매우 커짐을 시사한다. 달성 목표와 적용 산업은 특별한 트렌드가 확인되지 않았다(<Figure 8, 9>). 이는 품질 4.0의 달성 목표 및 적용 산업은 꾸준하고 고른 관심을 받고 있음을 시사한다. 트렌드 분석 결과를 종합해 볼 때, 품질 4.0 달성을 위한 시스템 조성에 근간을 이루는 기술 레벨 1과 2는 기술의 발전 트렌드에 따라 신속히 적응하는 속성을 지니고, 근본적인 목적 및 적용 산업을 나타내는 레벨 4와 5는 기술에 상관없이 안정적인 모습을 보인다.
5. 결 론
품질 4.0 관련 연구의 서로 다른 관점 및 여러 연구 간의 통합적 이해의 필요성에 따라, 본 논문에서는 관련 논문 1234개를 텍스트마이닝 및 기계학습을 활용해 분석하고, 그 결과를 해석함으로써 품질 4.0 선행연구의 동향을 파악하였다. 결과적으로 품질 4.0의 27개 연구토픽을 도출하고, 이를 5개 레벨로 분류(연결 인프라 기술–지능화, 자동화 및 최적화 기술–방법론 및 전략–달성 목표–적용 산업)하여 멀티레벨 프레임워크를 제안하였다. 또한 27개 연구토픽 간의 관계 분석을 통해 연관성을 파악하고, 이를 해석하였다.
본 논문의 결과물은 품질 4.0 관련 기술 개발 이슈부터 비즈니스, 달성 목적, 적용 산업을 아우르는 선행연구의 이해를 촉진하고, 학계의 연구 추진 및 토의에 기여할 것으로 기대한다. 본 연구는 품질 4.0 관련 키워드를 언급한 문헌 데이터 대부분을 분석했다는 점에서 포괄성을 가지며, 품질 4.0 관련 향후 출간될 연구를 제안된 연구토픽 및 프레임워크를 통해 이해할 수 있다는 점에서 활용성을 가진다.
2절에 언급한 선행연구와 본 연구의 결과물 간의 가장 큰 차이는 멀티레벨 관점에서 품질 4.0을 해석했다는 점이다. 선행연구에서는 동등한 레벨에서 품질 4.0 관련 요소를 해석해 왔다. 예를 들어 Seo et al.(2023)이 제안한 품질 4.0의 데이터 획득 및 분석기술, 연결과 통합, 리더십과 조직문화의 핵심요소는 모두 동등한 레벨로 해석된다. 또한 Sader et al. (2022)이 제안한 기술, 공정, 사람 관점에서의 핵심요소도 동등한 레벨에서 해석된다. 본 연구의 결과물은 동등한 레벨이 아닌 멀티레벨로 해석했다는 점에서 차별점이 있다. 본 연구에서 제안한 멀티레벨 프레임워크는 품질 4.0 달성에 필요한 기반기술부터 목적, 적용 산업분야까지 수준별로 구성되어 있기 때문에 품질 4.0의 구체적이고 추상적 내용 모두의 관계를 통합적으로 분석하고 해석하는데 효과적으로 활용된다. 또한 해당 프레임워크를 활용해 품질 4.0 연구논문의 경향성을 확인하는데 활용 가능하며, 미래 연구 이슈를 도출하는데도 활용 가능할 것으로 기대된다.
본 연구의 한계점 및 향후 과제는 다음과 같다. 첫째, 보다 다양하고 많은 데이터를 수집하여 분석할 필요가 있다. 예를 들어 최근 많은 논문이 출간되고 있는 Scopus 데이터베이스를 추가로 고려해 논문 데이터를 수집하거나, 논문 데이터가 아닌 다른 유형의 데이터(예: 뉴스, 특허 등)를 수집 및 분석하여 다른 관점(예: 활용성 측면, 기술적 측면)에서 품질 4.0을 더 깊이 이해하여 제안된 27개의 연구토픽을 수정 및 보완하는 것이 가능하다. 둘째, 본 논문에서 활용한 분석 방법은 각 논문의 세부 연구토픽을 해석하기보다는 여러 논문의 공통 연구토픽을 파악하고 분류하는데 활용 가능하다. 즉, 품질 4.0의 특정 측면(예: 방법론 측면에서 세부 내용 등)을 상세하게 살펴보기 위해서는 특정 연구토픽에 대한 체계적인 선행연구 리뷰가 필요하다. 셋째, 본 연구 결과물과 산업계에서 수행한 실증 결과(예: 프로젝트 수행 결과)를 통합하여 해석하는 것이 필요하다. 산업계에서 품질 4.0과 관련된 여러 환경 및 요구사항이 존재하기 때문이다. 이에 산업계 전문가들의 의견 수합이 필요하다. 이는 품질 4.0을 더 깊이 이해할 수 있도록 촉진하며, 실제 산업현장에서 사용할 수 있는 여러 실용적인 결과물(예: 품질 4.0 달성 절차, 주의사항 등)을 도출하는 데 활용될 수 있다.