이블 고장모형 하에서의 이중샘플링 T2 관리도의 경제적-통계적 설계 (이중샘플링 T2 관리도의 경제적-통계적 설계)
Economic-Statistical Design of Double Sampling T2 Control Chart under Weibull Failure Model
Article information
Abstract
Purpose:
Double sampling T2 chart is a useful tool for detecting a relatively small shift in process mean when the process is controlled by multiple variables. This paper finds the optimal design of the double sampling T2 chart in both economical and statistical sense under Weibull failure model.
Methods:
The expected cost function is mathematically derived using recursive equation approach. The optimal designs are found using a genetic algorithm for numerical examples and compared to those of single sampling T2 chart. Sensitivity analysis is performed to see the parameter effects.
Results:
The proposed design outperforms the optimal design of the single sampling T2 chart in terms of the expected cost per unit time and Type-I error rate for all the numerical examples considered.
Conclusion:
Double sampling T2 chart can be designed to satisfy both economic and statistical requirements under Weibull failure model and the resulting design is better than the single sampling counterpart.
1. 서 론
관리도는 제품의 품질특성 값의 변동을 시계열 관점에서 모니터링함으로써 공정이 관리상태에 있는지의 여부를 판단하기 위한 도구이다. 최초의 관리도는 1920년대에 개발된 Shewhart 관리도로, 경험적 근거로부터 중심선(μ)에서 ±3σX̄를 관리한계를 사용한 것이다. 이후 관리도에 관한 연구는 대부분 통계적인 측면에서의 성능을 개선하는 데 주력하여 오다가 Duncan(1956)이 최초로 X̄ 관리도에 비용의 개념을 도입한 경제적 모형을 제시하였다. 그 후 Saniga(1989)는 경제적 모형이 지닌 단점을 보완하기 위해 경제적 설계에 평균런 길이(ARL)와 같은 통계적 제약조건을 추가한 X̄-R 관리도의 경제적-통계적 설계를 제안하였다. 일반적으로, 경제적-통계적 설계는 추가 제약조건으로 인해 순수한 경제적 설계보다 더 많은 비용이 소요되지만 더 나은 통계적 성능을 제공하기 때문에 제품의 품질을 향상시키는 이점을 갖는다. 관리도의 경제적 설계에 대한 전반적 연구동향은 Montgomery(1980), Ho와 Case(1994), Montgomery(2004) 등에 잘 요약되어 있다.
X̄ 관리도가 지닌 단점 중의 하나는 비교적 작은 공정 평균의 이동을 감지하는 데 둔감하다는 점이다. 이러한 단점을 보완하기 위해 CUSUM 관리도, EWMA 관리도, VSI 관리도 등과 같은 다양한 대안이 제시되었는데, Croasdale(1974)이 제안한 이중샘플링 X̄ 관리도도 그러한 대안들 중의 하나로서 1단계 표본의 결과에 따라 필요할 경우 2단계 표본을 추가로 추출하여 공정 이상을 민감하게 감지하려는 시도이다. 후에 Daudin(1992)은 Croasdale의 모형을 개선한 이중샘플링 X̄ 관리도를 제시하였으며, Champ와 Aparisi(2008)는 Daudin의 모형을 다변량으로 확장한 이중샘플링 T2 관리도를 제안하였다. 또한 Torng 등(2009)은 이중샘플링 X̄ 관리도의 경제적 설계모형을 제안하였다.
대부분의 관리도에 관한 경제적 설계모형들은 이상원인의 발생 시간이 지수분포를 따른다는 가정 하에 개발되었다. 지수분포는 고장률이 시간이 지나도 일정하다고 가정하기 때문에 기계산업과 같은 분야의 공정시스템에는 오히려 고장률이 시간에 따라 증가한다고 가정하는 와이블분포가 더 적합할 수 있을 것이다. Hu(1984)는 이와 같은 점을 고려하여 이상원인의 발생 시간이 와이블분포를 따를 경우의 X̄ 관리도의 경제적 설계모형을 제시하였다. Hu가 제안한 모형은 고장률이 시간에 따라 증가함에도 불구하고 표본추출간격이 일정하다는 비현실적인 가정을 하였는데, Banerjee와 Rahim(1988)은 표본추출구간의 길이가 시간이 경과함에 따라 점점 짧아져서 각 표본추출구간에서 이상원인의 조건부 발생확률이 일정하게 되도록 Hu의 모형을 개선하였다. 이후에 Rahim(1993)은 시간이 경과함에 따라 고장률이 증가하는 일반적인 분포로 Banerjee와 Rahim의 모형을 확장시켰고, Yang과 Rahim(2006)은 Banerjee와 Rahim의 모형을 다변량 T2 관리도로 확장시켰으며, Seo(2013)는 Banerjee와 Rahim의 모형을 이중샘플링 X̄ 관리도에 적용하였다.
본 논문에서는 Yang과 Rahim(2006)의 모형에 근거한 다변량 T2 관리도에 Champ와 Aparisi(2008)가 제안한 이중샘플링 T2 관리도의 개념을 접목한 경제적-통계적 설계 모형을 제안하고자 한다.
본 논문의 구성은 다음과 같다. 2절에서는 이중샘플링 T2 관리도를 제안하고 그 절차를 설명한다. 3절에서는 제안한 설계의 비용함수를 유도한다. 4절에서는 다양한 수치 예를 통해 이중샘플링 T2 관리도와 단일샘플링 T2 관리도의 경제적-통계적 설계에서의 최적 설계모수 값을 비교한다. 5절에서는 통계적 제약과 여러 종류의 모수의 변화에 따른 민감도 분석을 수행하고, 6절에서는 본 논문에서 수행한 연구의 결과를 정리한다.
2. 가정 및 모형
Banerjee와 Rahim(1988)이 제안한 모형(이하 B & R 모형)에서는 고장시간이 와이블분포를 따를 경우에 X̄ 통계량이 관리도상의 조치한계선을 벗어나면 공정을 중단하고 이상원인의 발생여부를 조사한다고 가정하였다. B & R 모형의 가장 중요한 특징은 표본추출구간의 길이가 일정하다고 가정한 Hu(1984)의 경제적 설계모형과는 달리, 각 표본추출구간 내에서 처음으로 이상원인이 발생할 조건부확률이 일정하게 되도록 표본추출구간의 길이가 변한다는 점이다. Yang과 Rahim(2006)이 제안한 모형(이하 Y & R 모형)은 B & R 모형과 동일한 가정하에서 X̄ 관리도를 T2 관리도로 확장시킨 모형이다. 따라서 본 논문에서는 Y & R 모형의 이러한 가정을 그대로 유지하되, Champ와 Aparisi(2008)에서와 같이 조치한계선 안쪽에 경고한계선을 추가로 고려함으로써 T2 통계량이 조치한계선을 벗어나면 공정을 중단하고 이상원인의 발생여부를 조사하지만, T2 통계량이 경고한계선과 조치한계선 사이에 위치하는 경우 표본추출을 한 번 더 시행하여 관리이탈여부를 판정하는 이중샘플링의 개념을 적용한다. 이하에서는 와이블 고장모형 하에서의 이중샘플링 T2 관리도를 제안하고 3절에서 유도할 비용함수에 사용되는 몇 가지 결과들을 미리 정리해 보기로 한다.
2.1 이중샘플링(DS) T2 관리도
본 논문에서 개발하고자 하는 경제적-통계적 설계모형에 대한 가정에 앞서, Champ와 Aparisi(2008)가 제안한 이중샘플링(DS) T2 관리도에 대해 살펴보기로 한다. DS T2 관리도의 관리한계선과 각 영역은 <Figure 1>과 같이 나타낼 수 있다.
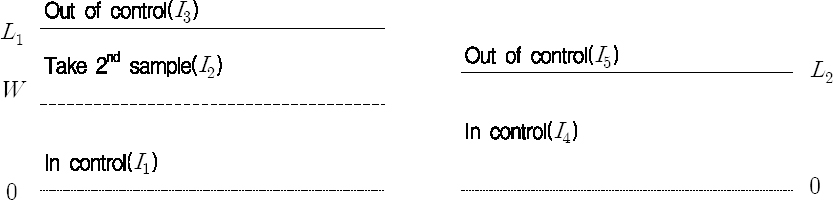
Graphical view of the DS T2 chart
DS T2 관리도에는 두 개의 T2 관리도가 사용되는데, 1단계 T2 관리도는 n1개의 j번째 표본에 대한 평균 X̄j, 1를 계산한 후
를 타점한다. 여기서 μ0와 Σ0는 각각 관리상태에서의 평균벡터와 공분산행렬이다. 2단계 T2 관리도는 (n1 + n2) 개의 표본에 대한 평균
를 타점한다. 1단계의 T2 관리도는 경고한계선의 관리한계계수가 W, 조치한계선의 관리한계계수가 L1 이고, 2단계의 T2 관리도는 조치한계선의 관리한계계수가 L2 이다. n1 개의 1단계 표본만으로 관리이탈여부를 판정할 수 없을 때 시간간격 없이 n2 개의 표본을 추가로 추출하고 (n1 + n2) 개의 표본을 모두 사용하여 공정의 관리이탈여부를 판정한다. DS T2 관리도의 절차를 흐름도로 표시하면 <Figure 2>와 같다.
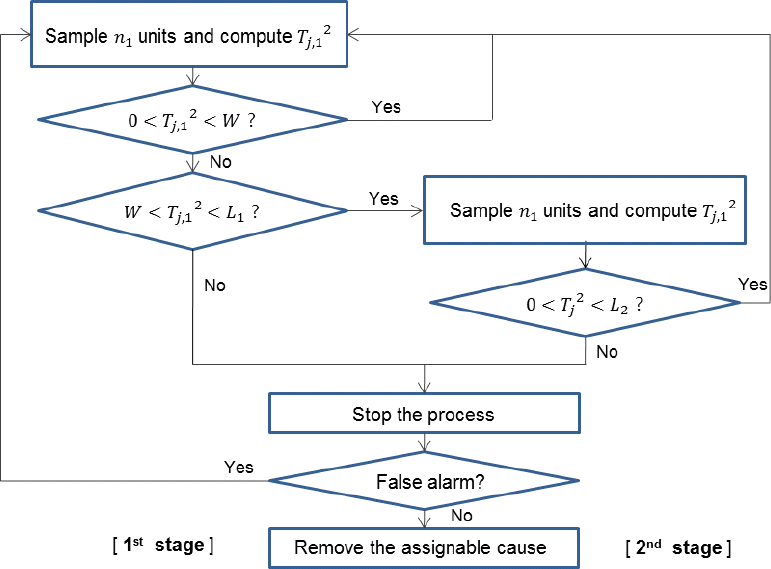
Flow diagram for DS T2 chart
2.2. 가정
2.2.1 공정관리에 관한 가정
공정은 관리상태에서 시작된다. 관리상태에서의 공정은 평균이 μ0 이고 공분산이 Σ0 인 다변량 정규분포를 따 른다.
이상원인이 발생하면 공정평균은 μ0 = μ1 + d로 이동한다.
이상원인의 발생시간은 척도모수가 λ이고 형상모수가 κ인 와이블분포를 따르며, 그 확률밀도함수는 다음과 같다.
(3)표본추출시점 h1, (h1 + h2), (h1 + h2 +h3), …마다 <Figure 2>의 흐름도와 같이 표본을 추출하여 공정의 변화를 탐지한다. 여기서 hj (j = 1, 2, …)의 값은 각 표본추출구간 내에서 처음으로 이상원인이 발생할 조건부 확률이 일정하게 되도록 한다.
표본추출과 관리도상의 타점에 걸리는 시간은 무시한다.
2.2.2 시간 및 비용모수에 관한 가정
표본추출비용은 고정비용 a단위당 추출비용 b로 구성된다.
경보가 거짓임을 판명하기 위해서 평균 S0의 시간이 걸리고, 비용은 평균 F가 소요된다.
이상원인을 찾아내기 위해 걸리는 시간은 평균 S1, 수리하기 위해 걸리는 시간은 평균 S2이며, 이상원인을 찾 아 제거하기 위해 소요되는 비용은 평균 ν이다.
관리상태 및 관리이탈상태 하에서 불합격품을 생산함으로 인한 시간당 기대비용은 각각 D0와 D1이다.
2.3 예비적 결과
2.3.1 DS T2 관리도의 각 영역별 확률
DS T2 도는 1단계 T2 관리도의 영역 I1 = [0, W], I2 = [W, L1], I3 = [L1, + ∞]와 2단계 T2 관리도의 영역 I4 = [0, L2], I5 = [L2, + ∞]구분된다.
표본추출 결과가 1단계에서 정상으로 판정될 확률은
이고, 미확정인 채 2단계로 넘어갈 확률은
이다. 또한 표본추출 결과가 2단계에서 정상으로 판정될 확률은 공정이 관리상태(d=0)일 경우
이고, 공정이 관리이탈상태(d≠0)일 경우
이다. 식 (7)에서
2.3.2 표본추출시점간의 간격 및 이상원인의 발생시점
Banerjee와 Rahim(1988)으로부터 j번째 표본추출구간의 길이 hj는 다음과 같이 나타낼 수 있다.
또한 각 표본추출구간에서 이상원인이 발생할 조건부확률은
으로 나타낼 수 있고, j번째 표본추출구간에서 이상원인이 발생할 확률은
로 나타낼 수 있다.
한편 이상원인의 발생시점과 직전 표본추출시점간의 평균 시간간격을 τ라고 정의하면 Banerjee와 Rahim(1988)으로부터 τ는 다음과 같이 나타낼 수 있다.
여기서 Γ(·)는 감마함수를 나타내고
3. 비용함수
본 논문에서 제안하는 경제적-통계적 관리도 설계모형은 주어진 통계적 제약조건 하에서 시간당 기대비용을 최소화하는 설계모수 (n1, n2, h1, W1, L1, L2)의 값을 찾는 데에 그 목적이 있다. 2절에서 기술한 공정관리절차는 일종의 재생보상과정이므로 시간당 기대비용을 주기당 총기대비용과 기대주기시간의 비로 표현할 수 있다(Ross, 1993). 따라서 이 절에서는 제안된 모형의 기대주기시간과 주기당 총기대비용을 유도하기로 한다.
3.1 기대주기시간
경보의 유무에 따라 공정의 관리상태를 <Table 1>과 같이 나타낼 수 있다.
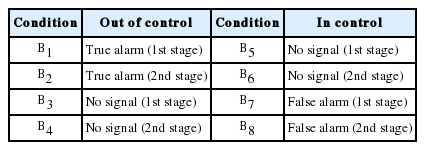
Conditions of process control
Tj(j = 0, 1, 2, …)를 j번째 표본추출시점 wj 에서의 잔여주기시간이라고 정의하면 Tj-1의 기댓값은 j번째 표본추출구간의 길이 hj 에 <Table 1>에 있는 8가지 경우의 조건부 기대잔여시간들의 평균을 합한 값으로 나타낼 수 있다. 즉,
pcj와 paj 를 관리이탈상태일 경우 j(j = 1,2)단계에서 경보가 없을 확률과 참 경보 확률로 각각 정의하고, αcj 와 αaj 를 관리상태일 경우 j(j = 1,2)단계에서 경보가 없을 확률과 거짓 경보 확률로 각각 정의하면, E(Tj|Bi) 와 P(Bi)는 <Table 2>와 같이 표현된다. 여기서 pcj, paj, αcj, 그리고 αaj의 값은 식 (4) ~ 식 (7)을 이용하여 쉽게 구할 수 있다.

Conditional expected remaining time for each process condition
식 (12)에 <Table 2>에 있는 각 경우의 기대잔여시간과 발생 확률을 대입하여 정리하면 다음과 같이 나타낼 수 있다.
여기서 pa = pa1 + pa2, αa = αa1 + αa2 를 나타낸다. 식 (13)에서 특히 j = 1 인 경우에는 기대주기시간 E(T)가 되며 다음과 같이 표현할 수 있다.
이제 식 (13)으로부터 E(Tj-1)(j = 1, 2, …)을 구해서 식 (14)에 대입하면 E(T)는 다음과 같이 나타낼 수 있다
식 (15)를 보다 간단히 표현하기 위해 Banerjee와 Rahim(1988)으로부터 다음의 보조정리를 인용하기로 한다
보조정리
1)
(16)2)
(17)
보조정리 1)에 의해
이고, 보조정리 2)에 의해
이므로 식 (15)에 식 (18)과 식 (19)를 대입하면 다음과 같은 기대주기시간에 관한 식을 얻게 된다.
3.2 주기당 총기대비용
주기당 총기대비용 E(C)를 구하기 위해서 Cj 를 j번째 표본추출시점 wj 에서의 잔여비용이라고 정의한다. 조건부 기대잔여비용은 현재 구간에서의 기대비용과 현재 구간 이후의 기대비용으로 나눌 수 있는데 이를 요약하면 <Table 3> 같이 나타낼 수 있다.

Conditional expected remaining cost
<Table 3>에서 R은 경보가 울릴 때까지의 표본추출비용과 품질비용의 합으로서 다음과 같이 나타낼 수 있다. (증명은 부록 B를 참조할 것.)
Cj를 j번째 표본추출시점 wj 에서의 잔여비용이라고 정의하면 Cj-1의 기댓값은 <Table 3>에 있는 8가지 경우의 조건부 기대잔여비용의 평균으로 나타낼 수 있다.
이제 식 (22)에 <Table 3>의 조건부 기대잔여비용과 <Table 2>의 해당 확률을 대입하여 정리하면 Cj-1의 기댓값은 다음과 같이 나타낼 수 있다.
식 (23)에서 특히 j = 1인 경우에는 주기당 총기대비용이 되며 다음과 같이 표현할 수 있다.
이제 식 (23)으로부터 E(Cj-1) (j 1, 2, …)을 구해서 식 (24)에 대입한 후, 보조정리 1)과 2)를 이용하여 정리하면 E(C)를 다음과 같이 나타낼 수 있다.
따라서 시간당 기대비용 E(A)는 식 (25)를 식 (20)으로 나누어 준 함수 형태로 표현된다. 여기서 E(A)는 6개의 설계모수 n1, n2, h1, W, L1, L2의 함수 형태이므로 DS T2 관리도의 경제적-통계적 설계 모형은 제1종 오류 확률(α)과 제2종 오류 확률(β)에 대한 통계적 제약 하에서 E(A)를 최소화하는 설계모수의 값을 찾는 것으로서 다음과 같이 나타낼 수 있다.
4. 수치 예제
이 절에서는 Yang과 Rahim(2006)에서 사용한 제지산업의 목재절단공정 예를 사용하여 본 논문에서 제안한 모형과 Y & R 모형의 비교 분석을 수행한다.
제지산업에서의 품질관리는 펄프 생산을 위한 나무 조각의 품질에서 시작된다. 나무 조각의 품질은 수분함량과 밝기라는 2개의 특성치로 측정된다. 통나무는 컨베이어 시스템에 의하여 나무 절단기에 공급되는데, 나무 절단기의 고장은 일반적으로 사용연수와 관련이 있다. 나무 절단기는 또한 목재에 못이나 돌과 같은 이물질이 있을 때 고장날 가능성이 높아진다. 나무 절단기의 톱니가 마모되거나 고장나면 공정이 완전히 중단되며 절단날의 교체와 생산 중단으로 인해 높은 손실비용이 발생한다. 따라서 높은 손실비용의 발생을 예방하기 위해 나무 조각의 수분함량과 밝기라는 2개의 특성치에 대해 T2 관리도를 사용하여 공정을 관리하고자 한다.
Yang과 Rahim(2006)은 나무 절단공정의 고장시간이 λ = 0.05, κ = 2인 와이블분포를 따르며, 두 특성치의 벡터 X가 관리상태에서 평균과 공분산행렬이 각각
인 이변량정규분포를 따르고, 관리이탈상태에서는 평균이
로 이동한다고 가정하였다. (따라서 관리이탈상태에서는 δ2 = d′ Σ-1d = 1 이 됨.) 또한 비용모수의 값은 a, $20.0; b, $4.22; D0, $50.0; D1, $950.0; Y, $500.0; W, $1,100.0을 가정하였고, 시간모수의 값은 S0, 0.25 시간; S1, 0.25 시간; S2, 0.75 시간을 가정하였다. 본 논문에서는 고장시간분포로서 Yang과 Rahim(2006)이 가정한 λ = 0.05, κ = 2 인 와이블분포 이외에도 그들이 사용한 척도모수 λ와 형상모수 κ값에 대한 7가지의 다른 예에 2가지를 추가한 총 10가지의 예를 사용하여, 본 논문에서 제안한 모형과 Y & R 모형의 비교 분석을 수행하였다. 비교를 위해 사용된 10가지 모수의 예는 <Table 4>와 같다.
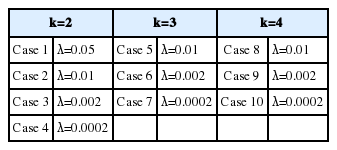
Weibull distributions used for comparison
두 모형의 비교를 위한 계산은 MATLAB(2012)의 유전자 알고리즘을 사용하여 통계적 제약조건하에서 시간당 기대비용을 최소화하는 값을 구하였다. 초기 모집단의 크기와 자녀 세대의 수는 각각 20과 100을 사용하였고, 통계적 제약조건은 Y & R 모형에서와 같이α0 = 0.0027과 β0 = 0.2를 사용하였다. 최적해의 수렴여부를 판단하기 위해 Yang과 Rahim(2006)의 최적해와 MATLAB의 최적해를 비교한 결과 비용함수값이 0.01% 내외의 차이로 일치함을 확인하였고, 최적해를 찾지 못하는 경우가 발생할 것을 대비해서 3회 이상 반복해서 안정된 값이 나올 경우를 최적해로 간주하였다. <Table 5>에 제시된 계산 결과를 분석해 보면 다음과 같은 몇 가지 사실을 확인할 수 있다.

Comparison of economic-statistical design of DS T2 chart and Y & R model
•DS T2 관리도는 제1종 오류 확률과 검정력 측면에서 Y & R 모형과 대등한 성능을 가지면서 Y & R 모형보 다 시간당 기대비용을 2.65% ~ 7.61% 정도 절감하는 효과를 나타냈다.
•DS T2 관리도의 첫 번째 표본추출구간 h1의 최적값은 Y & R 모형에 비해 약간 감소하였으며, 관리상태하에 서의 평균표본크기도 대폭 감소하였다. 또한 한 가지 경우(λ = 0.01, κ = 4)를 제외하면 조치한계선 L1 의 최 적값은 Y & R 모형의 L의 최적값에 비해 더 큰 반면에, L2의 최적값은 L의 최적값과 거의 유사한 값을 나 타냈다. 그 결과 DS T2 관리도가 Y & R 모형에 비해 표본추출비용과 공정중단비용을 줄임으로써 시간당 기
대비용을 감소시킨 것으로 해석할 수 있다.
•κ와 λ값 중 어느 하나가 고정된 채 고정되지 않은 나머지 모수의 값이 감소함에 따라 DS T2 관리도가 Y &
R 모형에 비해 시간당 기대비용의 절감효과가 증가하는 것으로 나타났다. 이러한 결과는 κ또는 λ값이 감소 함에 따라 평균고장시간이 길어지므로 DS T2 관리도의 상대적 유용성이 더 증가하기 때문일 것이다.
•κ를 고정시킨 채 λ가 증가함에 따라 표본추출간격이 급격히 감소하였는데, 이는 λ가 증가하면 평균고장시간 이 짧아지게 되어 고장발생시점의 예측이 어렵기 때문에 표본추출간격을 짧게 하여 이상원인의 발생여부를 신 속히 판단하는 것이 유리하기 때문일 것이다.
5. 민감도 분석
이 절에서는 여러 종류의 모수와 통계적 제약조건의 변화에 따른 제안된 모형의 설계모수의 민감도를 알아보기로 한다. 설계모수의 민감도 분석을 위해 해당 모수에 대한 민감도 분석의 경우를 제외하고는 와이블분포의 모수는 λ = 0.01, κ = 3 으로, 통계적 제약조건은 α = 0.01, 검정력 = 0.90으로, 공정평균의 이동 크기는 δ = 1.0 으로 고정하였으며, 시간모수와 비용모수는 Yang과 Rahim(2006)에서 가정한 값을 사용하였다.
5.1 α, 검정력, δ 및 λ의 민감도 분석
<Table 6>는α, 검정력, δ, λ 중 두 개의 모수를 함께 변화시킴에 따른 설계모수값의 변화를 보여 주고 있다. <Table 6>의 결과로부터 다음과 같은 결론을 도출할 수 있을 것이다.

Sensitivity analysis results for variation in two parameters
•α값이 증가함에 따라 표본추출간격(h1)에는 큰 변화가 없고 시간당 기대비용은 소폭으로 감소하는 것으로 나 타났다. 또한 검정력이 증가함에 따라 h1 과 시간당 기대비용은 대체로 증가하는 경향을 보이나 그 증가폭은 그다지 크지 않은 것으로 나타났다. α 의 감소 또는 검정력의 증가에 따른 시간당 기대비용의 증가 폭이 작다 는 것은 순수한 경제적 설계에 통계적 제약조건을 추가하더라도 시간당 기대비용의 증가가 크지 않음을 의미하는데, 실제로 <Table 5>의 경제적-통계적 설계를 순수한 경제적 설계와 시간당 기대비용 면에서 비교
한 결과 0.6% ~ 2.1% 정도 밖에 비용이 상승되지 않음을 확인하였다.
•δ값이 증가함에 따라 평균표본크기와 표본추출간격, 그리고 시간당 기대비용이 감소하는 것으로 나타났다. 이 러한 결과는δ값이 클수록 이상원인의 발견이 쉬워지므로 더 작은 크기의 표본을 더 자주 추출하게 되기 때문 일 것이다. (민감도분석에서δ가 0.5일 경우는δ에 대한 제약조건 값이 너무 작아서 해당 조건을 만족시키는 설계가 존재하지 않으므로 제외시켰다.)
•두 모수가 동시에 변화함에 따른 설계모수값에 대한 교호작용은 1단계 조치한계선(L1)을 제외하고는 그다지 크지는 않은 것으로 보인다. 특히 시간당 기대비용은 고려한 모든 경우에서 동일한 증가 혹은 감소 패턴이 유 지되므로 교호작용이 거의 없음을 알 수 있다.
5.2 시간 및 비용모수의 민감도 분석
시간 및 비용모수 값의 변화에 따른 설계모수 값의 변화는 <Table 7>과 같다. <Table 7>의 결과로부터 다음과
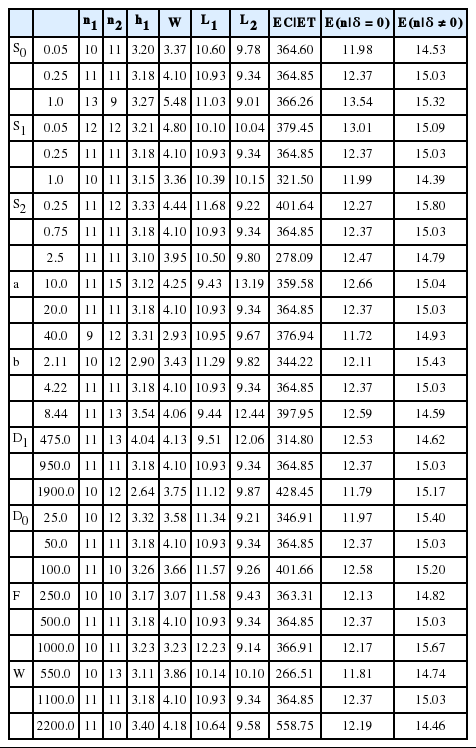
Sensitivity analysis results for time and process parameters
같은 결론을 도출할 수 있을 것이다.
거짓경보 탐색 기대시간(S0)이 증가하거나 이상원인 제거 기대시간(S2)이 감소함에 따라 경고한계선(W)과 1 단계 조치한계선(L1)은 증가하고, 2단계 조치한계선(L2)은 감소한다.
고정 표본추출비용(a) 또는 단위표본당 비용(b)이 증가함에 따라 표본추출간격(h1)도 증가한다. 이는 표본추출 비용의 증가를 상쇄하기 위해 표본추출간격이 길어진 결과라고 해석할 수 있다.
관리이탈상태 하에서의 불합격품의 생산으로 인한 시간당 기대비용(D1)이 증가함에 따라 h1은 감소한다. 이는 D1이 클수록 더 빈번하게 표본을 추출함으로써 신속히 경보를 울리는 것이 경제적이기 때문일 것이다.
관리상태 하에서의 불합격품의 생산으로 인한 시간당 기대비용(D0), 이상원인을 찾고 제거하는 기대비용(v), 그리고 거짓경보탐색 기대비용(F)은 설계모수 값에 뚜렷한 영향을 주지 않는 것으로 보인다.
6. 결 론
본 논문에서는 이상원인의 발생시간이 와이블분포를 따른다는 가정 하에서 이중샘플링(DS) T2 관리도의 경제적-통계적 설계모형을 제안하였다. 제안된 모형의 경제적 효용성을 단일샘플링(SS) T2 관리도 모형과 비교하기 위해 Yang과 Rahim(2006)에서 가정한 와이블분포의 척도모수 λ와 형상모수 κ에 대한 예들을 포함한 10가지 예에 대하여 최적의 설계모수 값과 시간당 기대비용을 계산한 결과, 다음과 같은 결론을 도출하였다.
첫째, 와이블 고장분포 하에서 본 논문에서 제안한 DS T2 관리도의 경제적-통계적 설계는 SS T2 관리도의 경제적-통계적 설계(Y & R 모형)에 비해 제 1종 오류 확률과 검정력 면에서는 대등하면서도 시간당 기대비용을 절감시키며, 또한 평균표본크기와 표본추출간격도 감소시키는 것으로 나타났다.
둘째, κ와 λ값 중 어느 하나가 고정된 채 나머지 모수의 값이 감소함에 따라 DS T2 관리도가 Y & R 모형에 비해 시간당 기대비용의 절감효과가 증가하는 것으로 나타났다. 그 이유는 κ 또는 λ값이 감소함에 따라 평균고장시간이 길어지므로 DS T2 관리도의 상대적 유용성이 더 증가하기 때문일 것이다. 또한 κ를 고정시킨 채 λ가 증가함에 따라 표본추출간격이 급격히 감소하였는데, 그 이유는 λ가 증가하면 평균고장시간이 짧아지게 되어 고장발생시점의 예측이 어렵기 때문에 표본추출간격을 짧게 하여 이상원인의 발생여부를 신속히 판단하는 것이 유리하기 때문일 것이다.
셋째, 민감도 분석결과에 의하면, α가 감소하거나 검정력이 증가함에 따른 시간당 기대비용의 증가 폭이 작은 것으로 나타났는데, 이는 순수한 경제적 설계에 통계적 제약조건을 추가하더라도 시간당 기대비용의 증가가 크지 않음을 의미한다. 또한 δ값이 증가함에 따라 평균표본크기와 표본추출간격이 감소하는 것으로 나타났는데, 이는 δ값이 클수록 이상원인의 발견이 쉬워지므로 더 작은 크기의 표본을 더 자주 추출하게 되기 때문일 것이다.
Appendices
부록 A. 사용 기호의 정의
nj: j(j =1,2) 번째 표본추출단계 표본 크기 (n1 < n2)
hj: j 번째 표본추출구간의 길이
S0: 거짓경보 탐색 기대시간
S1: 이상원인 발견 기대시간
S2: 이상원인 제거 기대시간
F: 거짓경보 탐색 기대비용
v: 이상원인을 찾고 제거하는 기대비용
a: 고정 표본추출비용
b: 단위표본당 추출비용
D0: 관리상태 하에서의 불합격품의 생산으로 인한 시간당 기대비용
D1: 관리이탈상태 하에서의 불합격품의 생산으로 인한 시간당 기대비용
αaj: 관리상태일 때 j(j = 1, 2)번째 표본추출단계에서 거짓경보가 울릴 확률
αa: 관리상태일 때 거짓경보가 울릴 확률 (αa = αa1 + αa2)
αcj: 관리상태일 때 j(j = 1, 2)번째 표본추출단계에서 경보가 없을 확률
αc: 관리상태일 때 경보가 없을 확률 (αc = αc1 + αc2)
paj: 관리이탈상태일 때 j(j = 1, 2)번째 표본추출단계에서 경보가 울릴 확률
pa: 관리이탈상태일 때 경보가 울릴 확률 (pa = pa1 + pa2)
pcj: 관리이탈상태일 때 j(j = 1, 2)번째 표본추출단계에서 경보가 없을 확률
pc: 관리이탈상태일 때 경보가 없을 확률 (pc = pc1 + pc2)
T: 주기시간
C: 주기당 비용
Tj: j번째 표본추출시점에서의 잔여주기시간 (T0 ≡ T)
Cj: j번째 표본추출시점에서의 주기내 잔여비용 (C0 ≡ C)
τj: j번째 표본추출구간에서 고장이 발생할 경우 그 구간 내에서 관리상태에 있을 조건부 기대시간
pj: (j - 1)번째 구간까지 관리상태에 있었다는 가정 하에서 j번째 구간에서 고장이 발생할 조건부 확률
wj: j번째 표본추출시점
κ: 와이블분포의 형상모수
λ: 와이블분포의 척도모수
τ: 이상원인의 발생시점과 직전 표본추출시점간의 평균 시간간격
W: DS T2 관리도의 1단계 경고한계선의 관리한계계수
L1: DS T2 관리도의 1단계 조치한계선의 관리한계계수
L2: DS T2 관리도의 2단계 조치한계선의 관리한계계수
δ: 공정평균의 이동 크기
부록 B. 식 (21)의 증명
R은 1단계 및 2단계에서 경보가 울릴 경우의 표본추출비용과 품질비용의 합이므로 R에 대한 식을 유도하기 위해 wj+i(i = 1, 2, …) 서시점에서 이동을 감지할 때까지의 표본추출 간격수와 그 확률을 구하면 <Table 9>와 같다. <Table 9>를 이용하여 R을 다음과 같이 표현할 수 있다.

Number of sampling intervals and its probability before alarm
그런데
이므로 식 (27)은 다음과 같이 나타낼 수 있다.
다음의 식 (32)와 식 (33)의 관계를 이용하여 식 (31)을 정리하면 R을 식 (21)과 같이 표현할 수 있다.