

1. 서 론
최근 글로벌 경제위기, COVID-19 팬데믹과 미국-중국 경제 갈등, 러시아-우크라이나 전쟁 그리고 금융당국의 금리 인상 등 다양한 국내외 변수로 인해 세계 경제와 국내 경제는 불확실성과 지속적인 변동성을 겪고 있다. 이러한 경제적 불안정성은 경제 주체들에게 중대한 영향을 미치며, 예측할 수 없는 환경을 조성하고 있다. 이에 따라 관련 산업과 학계에서는 경제 추세와 예측 연구에 더욱 강조를 두고 있다(HAN and Yu, 2022; Lee, 2021; Jang, 2020). 이러한 배경 속에서 경제지표들의 연구와 분석은 경제 전반적인 상황을 파악하고 미래의 경기 동향을 예측하는 데에 큰 도움을 줄 수 있다. 경기종합지수(Composite Index of Business Indicators, CI)는 경기순환을 예측하기 위한 대표적인 지표 중 하나로 정부 기관이나 민간에서 주기적으로 발표되고 있다(Kim, 2004; Lee, 2021). 경기순환은 경제활동의 팽창과 수축이 반복적으로 일어나는 주기적인 현상으로, 경기순환의 예측은 경제 정책 결정과 투자 결정에 중요한 정보를 제공한다. CI는 경제 전반적인 상황을 파악하는 데 사용되며, 경기선행지수(Composite Leading Index, CLI)와 경기동행지수(Coincident Composite Index, CCI), 경기후행지수(Lagging Composite Index, LCI)를 종합적으로 고려하여 산출한다. 그러나 CI는 지표 수집부터 검증 및 발표 주기가 길어 예측력에 제한이 있다(Lee, 2021).
본 연구의 목적은 다음과 같다. 우선, 다양한 경제지표들을 독립변수로 활용하여 경기순환을 예측하는 모델을 개발함으로써 경제 예측의 정확성과 신속성을 향상 시키는 것이다. CI는 지표 수집부터 검증 및 발표 주기가 길어 예측력에 제약이 있다. 따라서 AI 기반의 합성보조지수(AI-based Composite Supplementary Index, ACSI)를 구성하여 미래의 경기 동향을 신속하고 정확하게 예측할 수 있는 유용한 지표를 제시한다. 둘째, 연구에서는 인공신경망(Artificial Neural Network, ANN)을 활용한 다층퍼셉트론(Multilayer Perceptron, MLP), 순환신경망(Recurrent Neural Network, RNN), 장단기 메모리(Long Short-Term Memory, LSTM), 게이트 순환 유닛(Gated Recurrent Unit, GRU)와 같은 다양한 모델을 이용하여 경제지표들을 학습하고 예측 정확도를 평가한다. 이를 통해 최적의 모델을 선정하고, 경기 예측에 있어서 가장 효과적인 모델을 도출한다. 셋째, 실시간 경기 예측이 가능한 모델을 개발하여 경제 주체들이 경제지표들을 실시간으로 입력하고, 경기 동향을 신속하게 파악할 수 있도록 한다. 이를 통해 경제 주체들은 미래의 경기 동향에 대해 더욱 정확한 정보를 얻을 수 있으며, 이를 바탕으로 경영, 경제, 투자 등의 의사결정을 지원할 수 있다. 마지막으로, 본연구를 통해 개발된 AI 기반의 경기 선행 합성보조지수(AI-based Composite Leading Index, ACLI)와 AI 기반의 경기 동행 합성보조지수(AI-based Composite Coincident Index, ACCI)는 정부 기관, 금융 기관, 산업 분야 등 다양한 영역에서 활용될 수 있다. 경제정책의 수립과 투자 전략의 수립에 필요한 신속하고 정확한 경기 예측은 국가의 경제 안정성을 강화하고 경제 주체들의 의사결정을 지원하는데 기여할 것으로 기대된다.
2. 이론적 배경 및 선행연구
2.1 경기순환(Bussiness Cycle)
경기순환 이론은 경제 현상을 회복기(Recovery Phase), 호황기(Prosperity Phase), 후퇴기(Recession Phase), 침체기(Depression Phase)라는 네 단계로 설명하고 경제는 이러한 순환적인 패턴을 반복한다는 이론이다(Schumpter, 1939). 또한 Burns and Mitchell(1946)는 경기저점부터 경기정점까지의 상승국면인 확장기(Expansion Phase)와 경기정점부터 경기저점까지는 하강국면인 수축기(Contraction Phase)의 두 단계로 나누어 설명하고 있다. 경기순환은 장기적으로 반복과 주기적인 변동을 유지하며 확장기(회복기와 호황기)는 장기간 지속되고 수축기(후퇴기와 침체기는 비교적 단기간이다(Lee and Kim, 2015). 경기순환 주기를 정확히 예측하여 경제 성장을 안정적으로 유지하기 위해 경기순환 주기에 맞는 경제정책을 적시에 시행하는 것이 중요하다(Kim, 2015; Lee, 2021).
2.2 경기종합지수(Composite Index of Business Indicators, CI)에 관한 연구
경기순환 이론에 따른 각각의 경기순환주기를 예측 및 측정하는 대표적인 도구로 경기종합지수(CI)가 있다. CI는 우리나라의 대표적인 종합경기지표로 경제 전반적인 상황을 파악하는 데 사용된다. 경기변동의 국면을 판단하고 경기변동의 전환점과 경기순환 속도 및 진폭을 측정할 수 있도록 만들어졌으며 우리나라에서는 통계청이 1981년 3월부터 경제의 각 부문을 대표하는 경제지표들을 선정, 가공 및 종합하여 CI를 작성하여 매월 말경에 정기적으로 발표하고 있으나 자료수집 및 공표까지 2개월 이상의 시차가 발생한다(Kim, 2015; Kim, 2004; Lee 2021). CI는 경제 전반적인 상황을 파악하는 데 사용되는 지표로, CLI, CCI, LCI를 종합적으로 고려하여 산출된다. CLI는 CCI와 LCI에 대하여 선행성이 있으며, CCI는 LCI에 대하여 선행성이 있다고 알려져 있다. CI를 통해서 경기 현상에 대한 진폭과 전환점을 파악할 수 있다(Ko, 2021; Kim, 2015). CI는 경기가 상승할 때는 CI의 전월 증감률이 양(+)을 경기가 하강할 때는 음(-)을 나타낸다. 또한 경기변동의 진폭은 그 증감률의 크기를 통해서 경기국면, 경기전환점, 경기순환의 방향 및 속도까지 분석이 가능하다(Kim, 2015). CI는 경기 반영시차에 따라 CLI, CCI, LCI로 나눈다(Kim, 2015). CLI는 경제활동의 성장을 예측하기 위한 지표로, 경제활동의 변화에 앞서서 변화하는 경제지표를 의미한다. 예를 들어, CLI가 증가하면 경제활동이 성장할 가능성이 커진다. CCI는 경제활동의 성장을 파악하기 위한 지표로, 경제활동이 실제로 변화하는 지표를 의미한다. CCI가 증가하면 경제활동이 실제로 성장하고 있는 것으로 볼 수 있다. LCI는 경제활동의 성장을 확인하는 데 사용되는 지표로, 경제활동이 이미 변화한 이후에 나타나는 지표를 의미한다. GDP는 경제활동이 이미 발생한 후에 산출되는 지표로, LCI의 대표적인 지수라고 볼 수 있다. CI는 이러한 CLI, CCI, LCI를 종합적으로 고려하여 산출되며, 경제의 현재와 미래에 대한 예측에 매우 중요한 지표로 활용된다(Lee, 2021).
CI는 구성 지표의 계절 요인 및 불규칙적인 비정기적 요인을 제거하여 종합한 지표이나 장기적으로 상승하는 경제의 특성상 장기추세로 인해서 경기 변화를 정확하게 판단하기 어렵다. 이와 같은 이유로 인해 이를 보완하기 위해서 장기추세요인을 제거하고 경기변환을 판단하는 보조지표로 순환변동치를 사용하는데 통계청에서 CI와 같이 발표한다(Kim, 2004; Lee, 2009).
경기 국면 판단을 위한 CI 작성 기법에 관한 연구에서는 CI 작성을 위한 기법 개발에 초점을 두고 있다. 이를 위해 외국의 기법과 비교 및 분석을 통해 세 가지 방법으로 연구를 진행하였다. 첫째, 구성 지표의 표준편차 방식으로 표준화 및 기간 설정을 수행하였다. 둘째, 주성분 분석(PCA)을 이용하여 동행지표와 선행지표의 가중치를 적용하여 종합지수에 적용하였다. 셋째, 추세 조정은 GDP 추세 조정을 하지 않는 방법을 사용하였다. 이러한 방법들은 경기국면 판단의 정확도를 높이기 위한 중요한 요소들이다(Kim, 2001). 시계열 분석방법론을 이용하여 제주지역의 CI를 개편하는 연구에서는 X-12-ARIMA를 사용하여 계절 조정, H-P 필터, 교차 상관 등의 분석법들을 활용하여 동행지표 12개와 선행지표 8개를 선정하였다(Ko, 2021).
2.3 경기순환 및 경제에 영향을 미치는 요인
우리나라의 경기순환주기와 주식시장, 채권시장과 부동산시장 간의 시차적 관계를 연구한 논문에서는 주식시장이 9개월 정도 경기순환주기를 선행하고, 채권시장은 6~8개월의 시차로 경기순환주기를 후행하며, 부동산시장은 12개월의 시차 간격으로 경기순환주기를 후행한다고 분석하였다(Chi, 1998). 미국과 한국의 주식시장의 변동성과 금리, 환율, 유가 등의 거시경제변수 간의 상호 연관성을 비교 분석한 연구에서는 코스피 지수의 경우 주요 국제통화(원-달러, 원-유로, 원-위안 및 원-엔 환율)의 환율 변동과 깊은 관련성이 있으며 다우존스지수나 국제유가와 같은 경제지표와도 영향이 있다고 밝히고 있다(Lee and Baek, 2016). 유가 충격이 거시경제에 미치는 영향을 연구한 논문에서는 유가 상승 충격이 불황기에는 음의 영향을 미치고 호황기에는 유의미하지 않다고 해석하고 있다(Baek and Kim, 2020). Jang(2020)의 연구에서는 해외 요인인 국제 GDP 변화, 환율, 원자재 가격 등의 변화순서로 국내 중소기업 산업별 경영성과에 영향을 준다고 분석하였다. Park 등의 2020년의 연구에서는 주식시장의 정보인 주가지수가 거시경제 변수에 전이되는 속도가 빠를수록, 거시경제 변수인 소비자물가지수와 경기선행지수 등이 주식시장의 정보에 더 의존적이라고 분석하였다(Park, JUNG, and Byun, 2020). Chai(2009)의 연구에서는 OECD 19개국의 자료를 분석하여 실업급여제도가 경제성장에 긍정적인 영향을 미친다고 보며 관대한 실업급여제도 도입을 주장하고 있다(Chai, 2009). Kim 등의 2015년의 연구에서는 금융위기를 식별하고 예측할 수 있는 금융스트레스지수를 연구하였다(Kim, Park, and Kim, 2015). Lee(2021)의 거시경제변수와 주식 수익률 간의 관계를 연구에서는 통화량이 주식 수익율에 양(+)의 영향을 미친다고 분석하였다.
2.4 ANN 기반의 시계열 예측에 관한 연구
CI를 정확하게 측정하거나 예측하기 위해 기존의 연구자들은 다양한 방법을 통해 연구를 진행하였다. 특히 최근들어 빅데이터 및 머신러닝 방법론이 빠르게 발전하면서 ANN을 활용하여 시계열 자료를 분석하고 지수를 예측하는 모형이 많이 제시되고 있다. ANN 기반의 시계열 예측에 관한 연구에서는 주로 MLP, RNN과 LSTM을 적용하여 예측하는 연구가 진행되었다(HAN and Yu, 2019; Lee, 2021; Kim, 2020). 이를 통해 과거의 추세를 학습하여 다음 날의 추세를 예측할 수 있으며, 단기간에 한정 지어 해당 예측 결과를 결정에 활용할 수 있다는 장점이 있다. 해운 경기를 대표하는 화물 운임지수(BDI) 시계열 예측을 다룬 ANN 기반의 연구에서는 RNN과 LSTM을 적용하여 과거의 경향을 학습하고 BDI의 시계열 예측을 수행하였다. 이 연구에서는 기존 연구들에 비해 우수한 BDI 예측 결괏값을 도출하였고, 해당 결괏값으로 해운시장에 대한 단기간 경제 추세를 예측하였다(HAN and Yu, 2019). 건화물 운임지수 예측을 위해서 시계열 분해방법을 활용한 다른 연구에서는 MLP, RNN, LSTM모델에 시계열 분해 및 데이터 증강 방법을 적용하였다(HAN and Yu, 2022). 주식시장 예측을 다룬 Kim(2020)의 연구에서는 LSTM 모델을 사용하여 한국 주식시장에서 머신러닝 기법을 통한 포트폴리오 수익률을 예측하였다. 학습 기간을 1년으로 고정하고 예측 기간 및 운용 기간을 1, 3, 6개월로 나누어 분석하였으며, 수익을 얻는 상위, 하위 포트폴리오를 확인하였다. 울산 지역의 경제지표 예측모형개발을 연구한 Lee(2021)의 연구에서는 MLP모델을 활용하였으며, 울산 지역내총생산(Gross Regional Domestic Pruduct, GRDP)등을 예측력을 높이기 위해서 다양한 데이터를 활용해서 예측모형을 구축하고 우수한 예측력을 확인하였다. Kospi지수와 원-달러를 예측을 위해 앙상블 모델을 사용한 연구에서는 AdaBoost와 GRU를 결합한 모델이 ARIMA, LSTM, GRU보다 우수한 성능을 얻었다(Kwak and Lim, 2021). GDP 성장률을 예측하기 위해 GRU를 사용한 연구에서는 앙상블 모형을 다중으로 조합하여 부족한 데이터로 인한 과적합 문제를 해결할 수 있음을 증명하였다(Lee, Kim, and You, 2022).
2.5 선행연구 분석 및 한계
선행연구들의 분석 결과는 다음과 같다. 첫째, 우리나라의 CI를 구성하는 CLI와 CCI는 주식, 채권, 부동산, 금리, 유가, 환율, 다우존스지수 등과 상호 연관성을 가지고 있으며 세계경제지표의 영향을 받는다. 둘째, 기존의 통계적인 기법을 통해 지표의 추세와 계절성, 변동성, 주기 등을 고려하여 예측하는 방법 외에도 인공지능 모델을 이용하여 과거에서 미래로의 추세가 지속된다는 시계열모델의 전제를 이용하여 CI를 예측할 수 있다(Lee, 2021; HAN and Yu, 2019). 통계청에서 CI를 산출하는 경우는 지표들을 수집하고 분석하여 공표하기까지 시간이 한 달여 정도 소요가 되고 주기적으로 통계품질을 점검하고 있다.
선행연구를 요약하면, 경기순환 이론은 경제 현상을 회복기, 호황기, 후퇴기, 침체기라는 네 단계로 설명하며, 경기정점과 경기저점을 기준으로 확장기와 수축기로 구분한다. 경기종합지수(CI)는 경기변동을 예측하고 측정하는데 사용되며, 경제 전반적인 상황을 파악하는데 활용된다. 선행 연구들은 CI를 구성하는 경제지표들과의 상호 연관성을 분석하고, 통계적 기법이나 인공지능 모델을 활용하여 CI를 예측하는 방법을 연구하였다.
선행연구 들의 한계점으로는 다음과 같다. 첫째, 지수를 구성하는 지표들의 시차이다. 통계청에서 CI를 산출하는 경우는 선행연구들처럼 통계적방법을 이용하고 있으나 선행연구들처럼 MLP, RNN, LSTM 등을 이용하여 시계열 예측을 통한 지수를 발표하고 있지 않은 상황이다. 또한 지표 수집부터 공표까지의 시간이 경과 하면서 현재의 경기순환주기를 판단하기가 어려워지는 문제가 있다(Lee, 2021). 둘째, 다양한 독립 변수에 관한 연구가 부족하다. HAN and Yu(2019, 2022)의 BDI 시계열 예측 연구에서는 BDI를 구성하는 8가지 보조지표를 독립변수로 사용하여 BDI를 예측을 하였으나, 본 연구의 CI의 경우는 CCI, CLI, LCI가 서로 선행성, 후행성을 통해서 상호영향을 주고받고(Ko, 2021; Kim, 2015), 그 외의 다양한 거시경제지표들이 서로 영향을 미치기 때문에(Park, JUNG, and Byun, 2020; Lee and Baek, 2016; Jang, 2020), 수시로 변화하는 경기상황에 맞는 연구를 위해 상호 연관성을 고려한 다양한 독립변수들의 연구를 시도할 필요가 있다.
본 연구에서는 이러한 선행연구 들의 한계점을 극복하기 위해 다음과 같은 방법을 사용하고자 한다. 먼저, X-13-ARIMA-SEATS 모델을 이용하여 통계청에서 발표하는 장기추세요인을 제외한 CLI 순환변동치와 CCI 순환 변동치를 MLR, MLP, RNN, LSTM, GRU 모델 등을 통해 예측을 수행한다. 또한, 기존의 CLI와 CCI를 구성하는 경제지표 대신에 선행연구들에서 언급된 변수들을 경기순환에 영향을 미치는 독립변수로 사용한다. 이러한 방법을 통해 본연구는 선행연구들의 한계점을 극복하고 정확하고 신뢰할 수 있는 CI의 예측을 제시하고자 한다.
3. 연구 방법
3.1 예측 모델
MLR은 종속 변수(y)와 하나 이상의 독립 변수(x)간의 선형 관계를 분석하는 통계 기법이다. MLR의 독립변수가 강한 상관관계를 띄는 경우 다중공선성(Multicollinearity)이 발생할 수 있다. 다중공선성은 분산 팽창 요인(Variance Inflation Factor, VIF)을 통해 검증할 수 있는데, 주로 독립변수 간의 상관관계가 높을 때 발생한다. VIF가 일반적으로 10 이상이면 강한 상관관계로 인해서 다중공선성이 발생 되어 독립변수 간의 상관관계가 높아서 설명력이 감소하므로 해당 독립변수를 제거한다(Jeong and choi, 2022).
MLP는 ANN의 가장 기본적인 형태 중 하나이다. MLP는 여러 개의 Hidden layer를 가진 ANN 구조로 각 Hidden layer는 여러 개의 Neuron으로 구성되어 있으며, Input layer와 Output layer를 포함한 세 개의 Layer로 구성 된다(HAN and Yu, 2019; Lee, 2021). MLP는 주로 Supervised learning 에서 Classification와 Regression 문제를 해결하는 데 사용된다. Input layer는 각 Neuron의 입력으로 사용되고, 각 Neuron은 Weight와 Bias 값을 가진다. 각 Hidden layer와 Output layer의 뉴런은 Activation function을 통해 출력 값을 계산한다.
RNN은 입력과 출력의 길이가 가변적인 시퀀스 데이터에 효과적으로 적용할 수 있는 딥러닝 모델 중 하나로, 이전의 입력 값을 기억하고 현재의 입력 값과 함께 처리하여 출력 값을 만들어내는 모델이다. RNN의 구조는 기본적으로 Input layer, Hidden layer, Hidden layer로 이루어져 있다(HAN and Yu, 2019; Rumelhart, 1986).
LSTM은 RNN의 일종으로, 장기적인 의존 관계(long-term dependencies)를 학습할 수 있는 네트워크 구조의 모델이다. LSTM은 기본적으로 RNN의 구조와 유사하지만, 각 단계의 메모리 셀(memory cell)에 게이트(gate)라 불리는 구조를 추가하여 불필요한 정보를 제거하고 필요한 정보만을 보존하는 방식으로 학습한다. LSTM에서는 다음과 같은 총 3개의 게이트를 사용한다. 입력 게이트(Input Gate)는 현재의 입력 값에 대한 중요도를 결정한다. 삭제 게이트(Forget Gate)는 과거의 메모리 셀에서 어떤 정보를 제거할 것인지 결정한다. 출력 게이트(Output Gate)는 현재 메모리 셀의 값을 출력할 것인지를 결정한다(KANG, Cho, and Na, 2021; HAN and Yu, 2019; Hochreiter, Schmidhuber, 1997).
GRU는 LSTM과 마찬가지로 게이트 메커니즘을 사용하며 장기의존성 문제를 해결하기 위해 개발되었다. LSTM의 변형모형인 GRU는 update gate와 reset gate의 두 개의 게이트를 사용한다. GRU에서는 다음과 같은 총 2개의 게이트를 사용한다. 업데이트 게이트(Update Gate)는 얼마나 많은 이전 상태 정보를 유지할지 결정한다. 리셋 게이트(Reset Gate)는 얼마나 이전상태정보를 무시할지를 결정한다(Kwak and Lim, 2021).
3.2 제안 모델
3.2.1 AI 기반의 합성보조지수(AI-based Composite Supplementary Index, ACSI)
ACSI 구하는 방법을 단계별로 나타내면 다음과 같다.
첫째, training dataset으로 MLP, RNN, LSTM, GRU 모델을 각각 학습시킨다.
둘째, test dataset으로 학습한 모델들을 평가하고 식(1)과 같이 MSE값을 계산한다.
식(1)에서, n은 데이터 포인트의 수이며, yi는 실제값을 나타내고, y i ^
셋째, 식(2)처럼 MSE 가 가장 작은 모델을 선택하여 해당 모델을 이용하여 ACSI를 구한다.
ht 는 시점 t에서의 ACSI 를 나타내며, xt 는 입력 데이터를 나타낸다. fmodel 은 MSE 값이 가장 작은 MLP, RNN, LSTM, GRU 중 하나의 모델을 선택한다. 또한 식(3)과 같이 ACSI를 간단하게 나타낼 수 있다.
식(3)에서는 ht는 시점 t에서의 ACSI를 나타내고, m은 MLP, RNN, LSTM, GRU 중 하나의 모델을 의미한다. MSE(m, t)는 모델 m 을 사용하여 시점 t 에서 예측한 값과 실제 값 사이의 평균 제곱 오차이다. 따라서 위의 식은 시점 t에서 MSE 값이 가장 작은 모델을 선택하는 것을 의미한다.
3.2.2 ACSI모델 과 앙상블모델과의 차이
본 연구에서 제안하는 ACSI의 모델에서는 MLP, RNN, LSTM, GRU 등의 각 모델을 독립적으로 학습하고 MSE를 비교하여 최적 모델을 선택한 후 해당 모델의 예측 결과를 이용한다. 이로 인해 다양한 모델을 추가로 학습하여 예측 성능을 향상시킬 수 있다. 반면 앙상블 모델의 Bagging 기법은 동일한 모델을 다양한 훈련 데이터셋에 적용하여 다수의 모델을 학습하고, 다양한 모델의 예측 결과를 평균화하거나 투표 등의 방법으로 결합하여 최종 예측을 수행하여 다양성 측면에서 제한적이다.
3.2.3 ACSI모델 구축방법
본 연구에서 개발하고자 하는 ACSI의 모델 구축은 다음과 같이 3단계로 나누어 진행하였다.
첫 번째 단계에서는 데이터 수집 및 전처리를 하였으며 다양한 경제지표를 독립변수로 CLI와 CCI를 종속변수로 사용하여 ACSI 모델을 구축하였다. 본 연구에서는 사용하는 연구 대상 기간 데이터는 2006.12.01.~2023.04.21.이며(Table 4), 종속변수로 장기추세요인과 계절성을 제외한 CLI와 CCI를 순환변동치를 사용하였다. CLI와 CCI는 각각 월말 기준으로 값이 존재하여 같은 월 데이터를 말 일자 기준으로 동일한 값으로 대체하였다. 본 연구에서 제안하는 모델에 사용하는 경제지표들은 선행연구들에서 연구된 경기순환에 영향을 미치는 독립변수들로 구성하였으며 주식 관련 지표(5개), 채권 관련 지표 (4개), 부동산 관련 지표(1개), 원자재 관련 지표(5개), 환율 관련 지표(4개), 금리 관련 지표(1개), 지수 관련 지표(4개), 금융 관련 지표(1개), 실업률 관련 지표(2개), 통화량 관련 지표(1개)로 총 28개의 데이터들이다. 독립변수의 데이터들도 휴일의 경우 데이터가 수신이 안 되거나 월 기준으로 수신되는 경우 직전 데이터로 결측치를 대체했다. 독립변수 간의 스케일을 맞추기 위해서 정규화 기법(Normalization)을 적용하여 0~1의 실수 값으로 변환하였다. ACSI를 구성하는 독립변수와 선행연구는 Table 1과 같다.
MLR 모델을 적용한 연구를 하기 위해서 독립변수 간의 다중공선성을 확인하였는데 Table 2와 같이 대부분의 변수가 10 이상이 나와서 본 연구에서는 MLR을 이용한 시계열 예측은 제외하기로 한다.
두 번째 단계에서는 딥러닝 모델을 이용하여 ACSI를 구성하는 독립변수 간의 가중치를 학습하고 모델 성능을 평가하였다. 연구 기간(2006.12.01. ~ 2023.04.21.)의 Dataset은 Table 3과 같으며 4,142일간의 일자별 데이터를 인공지능 모델별로 학습을 시키고 학습된 모델을 테스트 기간(2019.12.31. ~ 2023.04.10.)의 1,036일 동안 평가를 하여 CLI와 CCI 대비 성과를 비교 측정한다. 경제지표 데이터의 경우 시간적으로 이전 데이터를 활용하여 새로운 데이터를 생성하거나 선형보간(Linear Interpolation) 등의 방법을 사용하여 새로운 데이터를 생성하였다.
모델의 성능을 개선하기 위해 하이퍼파라미터를 조정을 하고 데이터 증감기법을 적용하여 모델의 과적합(Overfitting)의 문제를 해결하고자 하였다(Table 4).
모델 성능 평가는 MSE(Mean Squared Error), RMSE(Root Mean Squared Error), MAE(Mean Absolute Error) 및 R2의 성과지표를 이용하여 실제의 CLI와 CCI 값과 차이를 비교하였다(Table 5).
세 번째의 실증 예측단계에서는 학습된 모델을 가지고 CLI와 CCI를 일별로 예측해본다.
4. 연구 결과
본 연구에서 개발하고자 하는 ACSI의 모델의 연구 결과는 세 단계로 나누어 볼 수 있다.
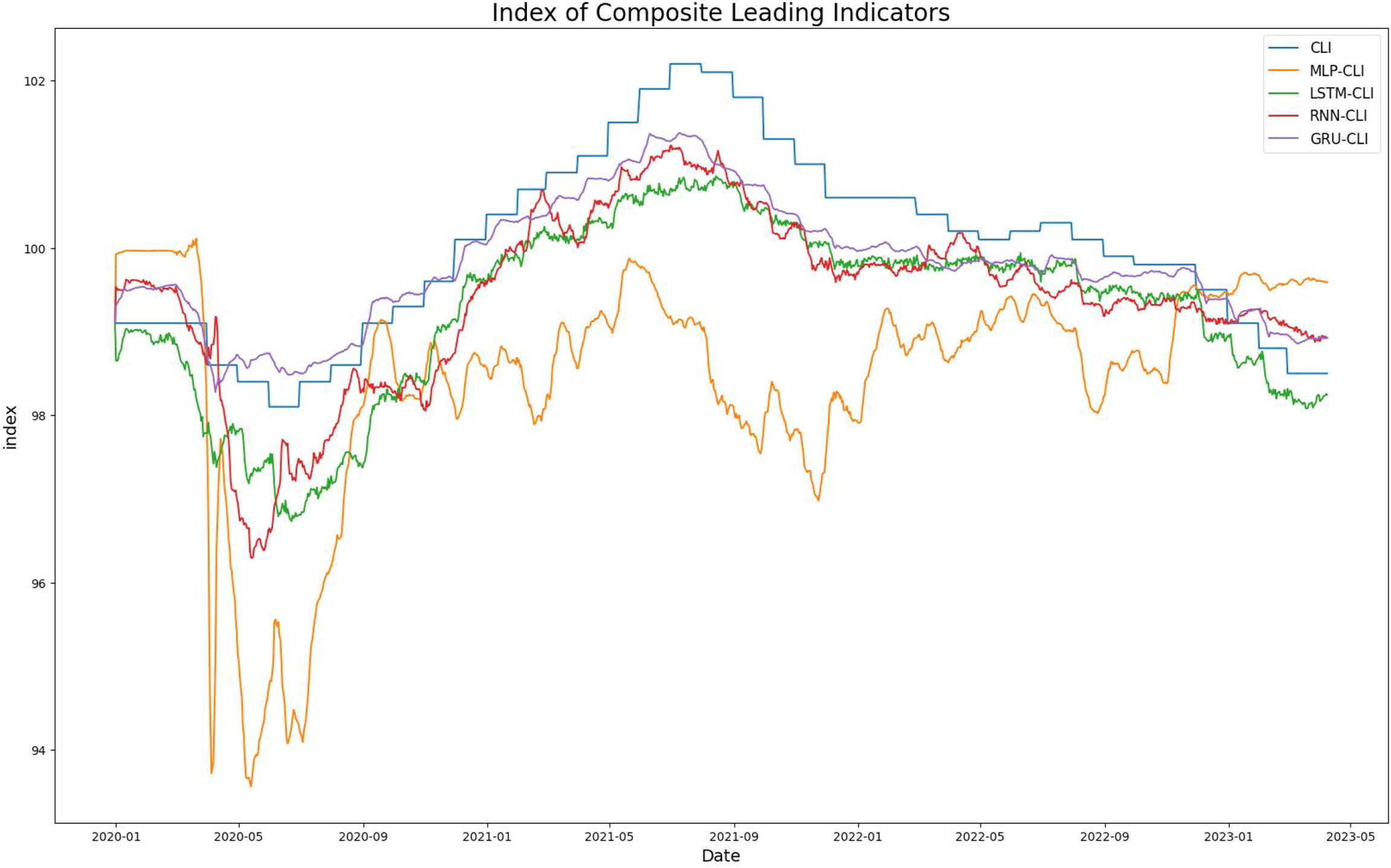
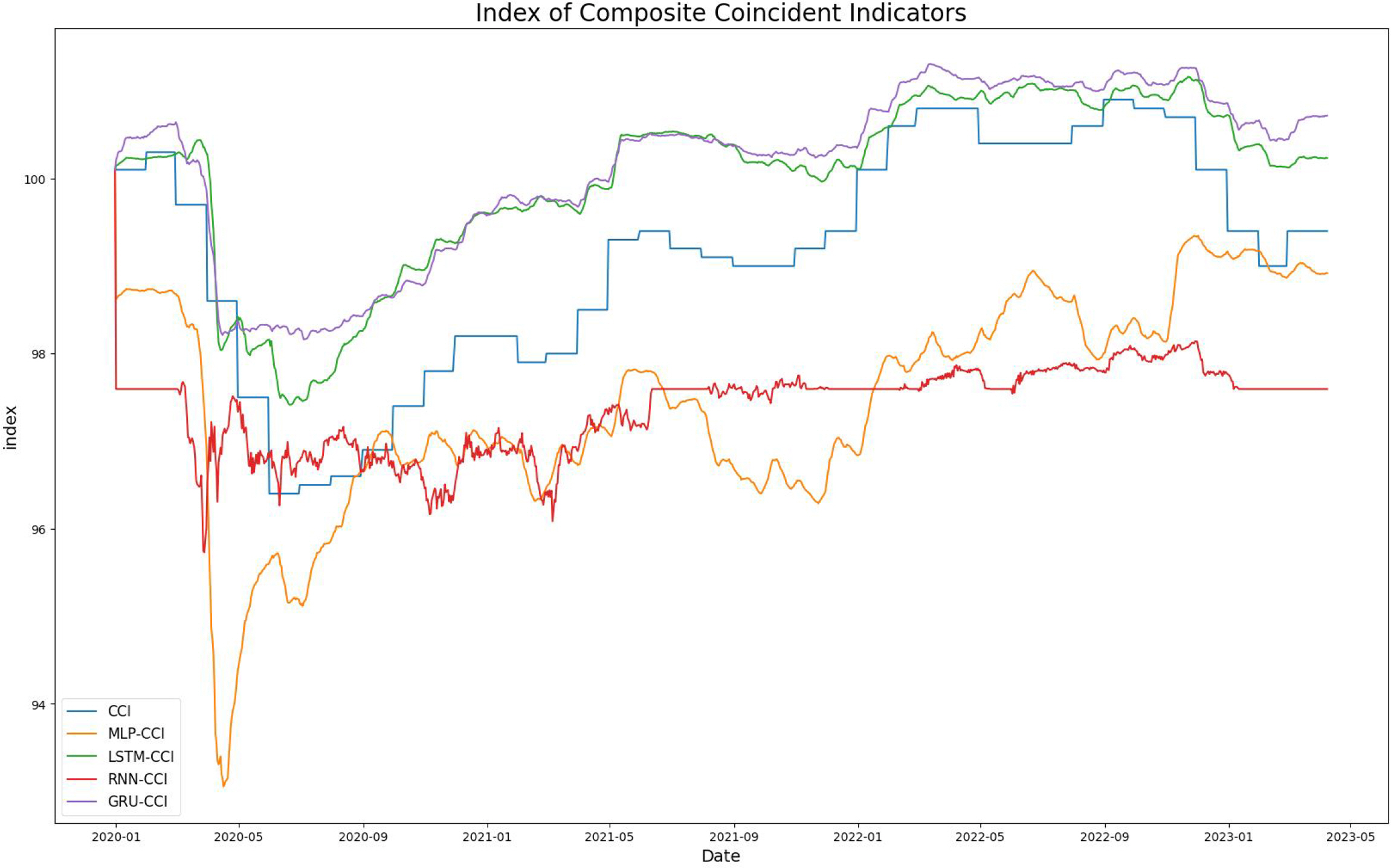
첫 번째 모델별 예측의 적합성을 확인하는 단계로 학습기간(2006.12.01.~2019.12.31.)의 데이터를 통하여 인공지능 모델별로 학습을 시키고 CLI와 CCI대비 성과를 비교 측정하였다. 학습 후 테스트기간(2020.01.01. ~ 2023.04.10.)동안의 CLI의 모델별 예측 그래프는 Figure 1과 같고 CCI의 테스트 기간의 모델별 예측 그래프는 Figure 2와 같다.
모델의 학습 기간의 Loss Fuction으로 MSE를 사용하였고, MLP, RNN, LSTM, GRU 모델의 성능을 MSE로 평가하였다. 그 결과, CLI의 MSE값은 MLP는 4.502, RNN은 0.629903, LSTM은 0.66747, GRU는 0.221607로 나왔으며, CCI의 MSE 값은 각각 MLP가 3.757717, RNN이 4.037547, LSTM이 1.028706, GRU가 1.293442로 나타났다. 결과적으로, CLI의 경우 예측에는 GRU, RNN, LSTM, MLP 순으로 성능이 우수했으며 CCI의 경우 LSTM, GRU, RNN, MLP의 순으로 성능이 우수했다. 실험 결과를 종합해보면, MLP 모델을 이용하여 CLI를 예측하는 경우 GRU 모델이 CCI를 예측하는 경우는 LSTM이 가장 적합하다(Table 6).
두 번째의 실증 예측단계에서는 학습된 모델을 가지고 ACLI와 ACCI를 일별로 예측한다(Table 6).
마지막으로 통계청에서 발표한 4월 실측치(X-13-ARIMA-SEATS)와 본 연구에서 제안하는 ACSI모델을 이용한 CLI와 CCI 값이 유의한 차이를 보이는지 비모수통계 검정중 하나인 Mann-Whitney U Test를 통해 실측치와 예측치의 유의성을 확인하였다(Table 7). 그 결과, CLI는 실측치(98.00)과 GRU가 유의한 차이를 보였으며(Z=-4.038, p<.001), GRU의 평균 순위(M=15.50)가 실측치의 평균 순위(M=5.50)보다 더 높게 나타났다. CCI는 실측치(99.9)와 LSTM가 유의한 차이를 보였으며(Z=-4.042, p<.001), LSTM의 평균 순위(M=15.50)가 실측치의 평균 순위(M=5.50)보다 더 높게 나타났다. GRU 모델을 통해 예측한 CLI와 LSTM 모델을 통해 예측한 CCI도 유의한 것으로 나타났다. 이러한 결과는 ACSI를 사용하여 ACLI와 ACCI 값을 높은 정확도로 예측할 수 있음을 시사한다.
본 연구에서는 MLP, RNN, LSTM 및 GRU 모델을 사용하였고, 데이터 증강기법과 하이퍼파라미터 튜닝을 통해 모델 성능을 개선하였다. 실험 결과, CLI에서는 GRU 모델이 CCI에서는 LSTM 모델이 높은 성능을 보였다. 또한 데이터 증강기법과 하이퍼파라미터 튜닝이 모델 성능 개선에 큰 영향을 미쳤다. 따라서, 본 연구에서 제안하는 ACSI의 모델은 통계청에서 매달 말에 발표하는 CI를 보완할 수 있을 것으로 보인다. 또한 ACSI 모델이 적절한 성능을 보인다는 것을 확인하였다. Table 8은 통계청에서 발표하는 통계품질 개선사항을 CI와 ACSI로 비교정리 하였다(Statistical Quality Control System. 2023).
5. 논의 및 결론
본 연구는 인공지능을 이용한 ACSI를 개발하여 경기변동을 예측하고 대처하는 데 있어 정확하고 효과적인 방안을 마련하여 예측모형의 품질을 향상하고자 하였다. 시계열 데이터의 예측을 위해 MLP, RNN, LSTM, GRU모델을 비교하였고 실험 결과, CLI의 경우 GRU 모델이 MLP, RNN, LSTM 모델보다 더 정확한 결과를 보였으며, GRU 모델의 MSE는 0.221607이다. 또한, CCI의 경우는 LSTM모델이 다른 모델보다 더 정확한 결과를 보였으며, LSTM 모델의 MSE는 1.028706이었다. 2023.05.31.에 통계청에서 발표한 2023년 4월 CLI의 실측치는 98.00이고 CCI는 99.90이며, 실측치와의 비교를 통해 ACLI의 10일간의 평균값 98.9419(GRU)과 ACCI의 평균값은 100.2241(LSTM)로 실제값과 유사한 결과를 얻었다. Mann-Whitney U Test를 통해 GRU와 LSTM 모델을 통해 예측된 ACLI와 ACCI 값은 실측치와 유의한 차이를 보임을 확인하였다(p<.001). 예측된 ACLI와 ACCI 값의 평균 순위는 실측치의 평균 순위보다 유의하게 높았다. 이러한 결과는 ACSI를 사용하여 ACLI와 ACCI를 높은 정확도로 예측할 수 있음을 시사한다.
본 연구는 선행연구와 다음과 같은 차이점이 있다. 첫째, 모델의 적용 대상이 경제 전반의 지표를 대상으로 하고있다. 기존 연구들은 주로 특정 지표(화물 운임지수, 주식시장 등)의 예측에 집중했다면, 이 연구는 경제 전반의 지표를 종합적으로 고려하여 경기종합지수의 보완을 목표로 한다. 둘째, 인공지능 기술의 활용이다. 이 연구에서는 인공지능 기술인 신경망 모델(ANN)을 활용하여 시계열 데이터의 예측에 적용한다. 특히, MLP, RNN, LSTM, GRU와 같은 다양한 신경망 구조를 사용하고 최적의 모델을 찾아 지표성능을 개선하고 예측 정확도를 높인다.
셋째, 독립변수의 다양성과 종합성이다. 본 연구에서는 다양한 독립변수들을 종합적으로 고려하여 경기종합지수의 예측에 활용한다. 기존 연구들과는 달리 코스피지수, 코스닥지수, 금융 지표, 환율 등 다양한 경제지표들을 포함하여 종합적인 예측 모델을 구축한다. 이를 통해 보다 종합적이고 실제에 가까운 지표를 제시하여 CI의 예측 정확도를 향상 시켰다.
본 연구의 주요 결론은 다음과 같다. 첫째, ACSI는 CI의 예측성능을 향상시킬 수 있다. 다양한 독립변수를 활용하여 예측 모델의 복잡도를 높일 수 있어, 예측성능이 기존 모델보다 더욱 향상될 수 있다. 기존 모델에서 예측이 어려웠던 극단적인 시장 상황에서도 정확한 예측이 가능하며 학습을 통하여 예측 모델을 지속적으로 개선이 가능하다. 둘째, ACSI는 CI의 근본적인 문제인 발표 주기를 단축할 수 있다. 기존 CLI와 CCI는 발표 주기가 길어 실시간 경제 동향을 파악하기 어려웠지만, ACSI는 시장의 경제전망 및 경제 동향을 빠르게 파악할 수 있다. 셋째, ACSI는 다양한 데이터를 독립변수를 활용하여 경기순환 예측 정확도를 높일 수 있다. 인공지능 기술을 활용하여 머신러닝 기반의 예측 모델을 구축함으로써, 예측의 정확도와 일관성을 높일 수 있으며 새로운 지표를 활용할 수 있어 기존 지표보다 더욱 정확한 경제전망을 제공할 수 있다. 또한 기존의 경제지표 외에도 다양한 산업 분야의 데이터를 활용할 수 있다. 넷째, 실험 결과에서 제시된 MSE 값과 Mann-Whitney U 검정 결과를 통해 ACSI 모델의 신뢰성과 타당성을 확인하였다. MSE 값은 GRU 모델을 통해 예측된 ACLI와 LSTM 모델을 통해 예측된 ACCI의 오차를 나타내는데, 이 값이 매우 낮게 나타났다는 것은 ACSI 모델의 예측 정확도가 높음을 의미한다. 또한, Mann-Whitney U 검정 결과에서는 ACSI 모델을 통해 얻은 ACLI와 ACCI 값이 실측치와 유의한 차이를 보여줌으로써 모델의 타당성을 입증하였다. 이러한 결과들은 ACSI 모델이 경기순환 예측에 있어서 신뢰성과 타당성 측면에서 문제가 없음을 확인할 수 있음을 시사한다.
마지막으로, 본 연구는 경기순환 이론과 경기종합지수에 대한 이론적 이해를 확장하고 발전시키는 데 기여할 수 있으며 연구에서 수집,분석한 데이터는 새로운 시각과 통찰력을 제공할수 있다. ACSI 개발을 통한 경기 예측 모델과 예측 결과는 기업들의 의사결정에 도움을 주고 경제정책 결정자들에게 정확하고 신뢰할 수 있는 정보를 적시에 제공하여 경제 정책을 시행하는데 도움을 줄 수 있다.
본 연구의 한계점으로는 ANN 기반의 시계열 예측 모델인 ACSI의 설명 불가능성이 있다. 이를 극복하기 위해 향후에는 XAI(Explainable Artificial Intelligence)의 연구가 필요하다(Hong, Hong, Oh, Kang, Lee and KANG, 2023). 이러한 연구는 모델의 예측 결과를 해석하고 신뢰성을 높이는 데 도움을 줄 수 있다. 또한, 통계적 검증도 중요한 요소이다. 예측 모델의 성능을 평가하기 위해 신뢰도 있는 통계적 검증 절차를 수행해야 한다. 이를 통해 모델의 예측력과 안정성을 검증하고, 실제 경제 현상에 대한 설명력을 강화할 수 있다. 추가적으로 다양한 독립변수들과 모델을 연구하고 적용하는 것이 필요하다. 특히 Transformer 모델과 같은 다양한 최신 모델을 시계열 예측에 적용하여 모델의 예측성능을 향상 시키는 방법을 탐구하는 것은 의미가 있다. ACSI 모델에 식스시그마를 적용하여 지수의 품질을 개선하는 것도 한 가지 방법이다(Kim and Kim, 2022). 식스시그마의 원칙과 방법론을 활용하여 ACSI 지수의 설명력과 예측 정확도를 향상 시키고, 실제 경제 현상에 대한 이해와 해석력을 향상시킬 수 있다. 그러나 ACSI 모델에 식스시그마를 적용하기 위해서는 추가적인 연구와 개발이 필요하며, 이를 통해 ACSI 모델의 신뢰성과 타당성을 더욱 향상시킬 수 있다.향후 연구에서는 XAI의 적용, 통계적 검증 그리고 다양한 모델의 연구 및 비교를 진행하여 모델의 한계를 극복하고 정확하고 해석 가능한 경기 예측 모델을 발전시킬 필요가 있다. 이를 통해 경제 주체들에게 보다 신뢰성 있는 경제 예측 정보를 제공할 수 있을 것으로 기대한다.